| Abbildung 6.1: | Clojure Inspector |
Clojure bedient sich der umfangreichen Sammlung von Bibliotheken aus dem Java-Umfeld. Dadurch bietet Clojure trotz seines jugendlichen Alters den Anwendern eine reiche Auswahl. Darüber hinaus entstehen mehr und mehr native Bibliotheken, oft als Wrapper um bestehende Bibliotheken und Funktionen von Java, um sie in Clojure leichter und idiomatischer verwenden zu können. ContribHier ist die Sammlung Clojure Contrib [35] besonders hervorzuheben. Diese kann als eine Art Staging-Area betrachtet werden, aus der besonders gute oder wichtige Bibliotheken unter Umständen den Sprung in den Sprachkern von Clojure schaffen. Clojars und weitereDaneben existiert mit Clojars [51] eine weitere Anlaufstelle für interessante Bibliotheken. Dabei ist Clojars selber bereits in Clojure geschrieben. Viele Entwickler, die ihre Leidenschaft für Clojure bereits entdeckt haben, stellen ihre Projekte auch auf den großen Git-Hostern wie github [20] oder Gitorious [63], um nur zwei willkürlich zu nennen, bereit.
Dieses Kapitel stellt einige Bibliotheken aus Clojure-Contrib und dem Sprachumfang von Clojure 1.2 vor.
Operationen auf Dateien sind ein elementarer Baustein fast aller Programme; dementsprechend ist diese Funktionalität in jeder ernstzunehmenden Sprache enthalten. In Java geschieht dies durch Eingabe- und Ausgabe-Streams, die unabhängig vom eigentlichen Medium (Datei, Netzwerk, Arbeitsspeicher) das Lesen bzw. Schreiben auf der Basis von Bytes erlauben. Eine Menge von „Reader“-Klassen, die auf diesen Streams operieren, vereinfachen den Umgang mit textbasierten Dateien (zeilenweise Lesen, Zeichensatzkodierung).
In früheren Versionen von Clojure wurden diese Klassen durch die Contrib-Bibliothek duck-streams verfügbar gemacht. Einige Mehrfachmethoden (siehe Abschnitt 2.12.4) gestatteten es beispielsweise, einen Reader aus einem java.io.File, einer java.net.URL oder einem String, der als URL oder Pfadangabe interpretiert wird, zu erzeugen.
Ab Clojure 1.2 sind diese Funktionen in der Kernbibliothek im Namespace clojure.java.io enthalten. Die Implementation basiert nun auf Protokollen (siehe Abschnitt 5.2) und ist nebenbei bemerkt ein gut lesbares Beispiel für deren Einsatz.
Ein Beispiel für die Benutzung ist in Abschnitt 3.4.4 enthalten; dort wurden mit einem Reader die Zeilen einer Logdatei in eine Sequence von Strings umgewandelt.
Als zweites Beispiel folgt hier eine Funktion, die einerseits Dateien kopieren, aber darüber hinaus auch Dateien aus dem Internet herunterladen kann.
In diesem Beispiel werden zwei Streams geöffnet (das Makro with-open übernimmt das Schließen) und der Inhalt per copy kopiert.
Gerade im Umfeld von Java hat sich die Verarbeitung von XML-Daten als Standard etabliert. Erwartungsgemäß existieren qualitativ hochwertige Klassen, die diese Verarbeitung erleichtern.
Clojure bringt in seinem Sprachumfang bereits einen einfachen Parser für XML-Dateien mit. Dieser findet sich im Namespace clojure.xml. Die beiden wichtigen Funktionen sind parse und emit. Erstere erwartet als Argument einen Dateinamen, einen Stream oder einen URI und liefert eine Map zurück. Die Funktion emit hingegen erwartet genau eine solche Map, wie sie parse liefert, und gibt den XML-Inhalt auf *out* aus.
Die Bibliothek clojure.contrib.lazy-xml ermöglicht es, die Baumstruktur einer XML-Datei als eine Lazy Sequence anzusprechen. Im Gegensatz zu anderen Parsern gibt es damit keine Eltern-Kind-Beziehung zwischen den enthaltenen Knoten; die Reihenfolge der Elemente in der Sequence entspricht einer Tiefensuche im Baum.
Diese Funktionalität wird in Abschnitt 4.5.1 aus Java heraus verwendet. Zum Vergleich ein reines Clojure-Programm, das dieselbe Ausgabe liefert:
Dessen Verwendung demonstriert das folgende Beispiel.
In beiden Programmen müssen die Zeichenketten aus Elementen mit dem Typ :characters extrahiert werden, die unmittelbar auf die öffnenden Tags link bzw. title folgen. Im Java-Programm wurden Variablen verwendet, um die Position innerhalb der Sequence zu notieren und so die richtigen Werte zu selektieren. In einem funktionalen Stil ist ein anderer Ansatz wünschenswert.
Algorithmus
In der modernen Softwareentwicklung ist die Verifikation bezüglich der Korrektheit einer Implementation ein zentraler Bestandteil des Entwicklungsprozesses geworden.
Framework
In folgendem Beispiel ist ein Lindenmayer-System [55] als Clojure-Sequence implementiert. Ein solches System ist eine Variante einer formalen Grammatik, in der Zeichenketten aus einem Ausgangswert und einer Menge von Produktionsregeln erstellt werden. Die Funktionalität wird durch zwei Tests von konkreten L-Systemen überprüft, wobei einer der Tests zu Demonstrationszwecken ein falsches Ergebnis erwartet und daher immer fehlschlägt.
Ausführen der Tests
Enge Bindung
Diese Kosten können eingeschränkt werden, indem der Wert der Variablen *load-tests* auf false gesetzt wird; der Testcode muss zwar immer noch geparst werden, aber die Testfunktionen werden nun nicht mehr angelegt. Selbstverständlich ist es ebenso möglich, die Tests in einer separaten Datei zu definieren und die Problematik damit zu umgehen.
In vielen Fällen lässt sich eine Aufgabenstellung am einfachsten durch das Aufrufen eines externen Programmes bewältigen. Für diesen Zweck gibt es in Clojure die Bibliothek clojure.java.shell. Einige einfache Anwendungsbeispiele sind bereits in früheren Kapiteln enthalten.
Optionale Parameter
C-Programm
Sowohl der Name des Namespace als auch der Name der Funktion sh können bei UNIX-Benutzern eine Assoziation zu den dort üblichen Kommandozeileninterpretern auslösen, tatsächlich handelt es sich jedoch um einen Wrapper um die Methode exec der Runtime-Klasse.
In Clojure 1.1 war diese Funktionalität in der Contrib-Bibliothek unter dem Namen clojure.contrib.shell-out verfügbar, seit Version 1.2 ist sie in der Clojure-Kernbibliothek enthalten.
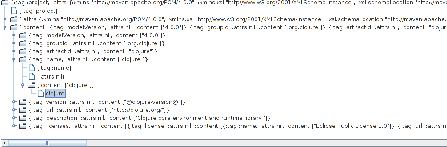
In Clojure bereits enthalten ist ein einfacher grafischer Inspector für baumartige Datenstrukturen. Er befindet sich im Namensraum clojure.inspect. Im Zusammenspiel mit der Funktion parse aus dem Namespace clojure.xml lassen sich so XML-Dateien betrachten. Das Resultat des folgenden Aufrufs zeigt Abbildung 6.1.
Die Bibliothek clojure.walk enthält Funktionen, um einen Baum aus (nahezu) beliebigen Clojure-Datenstrukturen zu traversieren und optional sogar zu manipulieren.
Die Bibliothek beinhaltet einige Anwendungsbeispiele, anhand derer die Benutzung und auch das Potenzial deutlich werden. Da Clojure-Sourcecode vom Reader als ein Baum dieser Datenstrukturen geliefert wird, eröffnet sich die faszinierende Möglichkeit, zur Laufzeit auf dem aktiven Code zu operieren.
Das folgende Beispiel demonstriert, wie der Code aller Funktionen eines Namespace bezüglich der Verwendung eines bestimmten Symbols untersucht wird. Die Funktionalität des Auffindens aller Aufrufstellen einer Funktion ist Benutzern moderner IDEs wie zum Beispiel NetBeans vermutlich bekannt.
In den Zeilen 6–8 wird der Code einer Funktion als String geladen und mit read-string in eine durchsuchbare Datenstruktur umgewandelt; dazu wird mit Hilfe von source-fn aus clojure.repl der Quelltext ermittelt. Das Binding der Variable *read-eval* verhindert, dass der Code beim Lesen evaluiert wird. Diese Variable bezieht sich nur auf den seltenen Fall, wenn der in Tabelle 2.18.2 in Abschnitt 2.18.2 kurz erwähnte EvalReader – in Form des Reader-Makros #= – vorkommt. Da in dieser Funktion jedoch sehr viel Code gelesen wird, ist diese Vorsichtsmaßnahme angebracht.
Der erzeugte Baum, der den Quelltext widerspiegelt, wird in walk-source durchlaufen und dabei jedes Element in der anonymen Funktion (Zeile 13–14) auf Gleichheit mit dem gesuchten Symbol getestet. Das lokal gültige Atom zeigt hier, dass es prinzipiell möglich ist, Statusinformationen lokal zu speichern. Im Sinne funktionaler Programmierung ist das sehr selten guter Stil und hier auch mehr zu Demonstrationszwecken verwendet. Das Durchsuchen aller Funktionen eines Namespace geschieht in diesem Beispiel parallelisiert durch die Verwendung von pmap in Zeile 20, da dieser Vorgang relativ aufwendig ist und die einzelnen Suchvorgänge offensichtlich voneinander unabhängig sind. Wie groß der Performancegewinn ist, ist allerdings fragwürdig: Die Operation ist vermutlich I/O-gebunden, hängt also eher von der Geschwindigkeit des Speichermediums ab. Daher zeigt auch der Kommentar ab Zeile 23 eine alternative Implementation ohne Parallelisierung.
Abschließend erfolgt ab Zeile 27 die Definition der Hauptfunktion find-usage-in-ns, die mit einem oder zwei Argumenten aufgerufen werden kann. Die folgende REPL-Sitzung zeigt die Verwendung dieser neu definierten Funktion:
Die Hilfsfunktionen für den Einsatz an der REPL sind ein weiteres Beispiel für eine Bibliothek, die ihr Dasein in der Contrib-Sammlung begonnen hat. Seit Version 1.2 ist sie (zumindest teilweise) im Namespace clojure.repl Bestandteil von Clojure selbst. Je nach verwendeter IDE kann dieser Namespace an der REPL bereits geladen sein. Die interessanteste Funktion aus dieser Sammlung ist source, die den Quelltext von in Clojure definierten Vars ermittelt und anzeigt. Dazu greift sie auf die Metadaten an den Vars zurück, die während des Kompilierens angelegt wurden. Beispiele hierzu haben sich im Verlauf des Buches bereits ergeben.
Die bisher nur in der Contrib-Bibliothek verfügbare Funktion show listet (optional gefiltert) die Methoden und Variablen einer Klasse (beziehungsweise einer Objektinstanz) auf.
Die Pretty-Print-Bibliothek – seit Version 1.2 von Clojure im Sprachstandard im Namespace clojure.pprint enthalten – erlaubt die Ausgabe von Daten und Datenstrukturen mit besserer Lesbarkeit. Die zentrale Funktion dabei ist pprint. In diesem Buch haben die Codebeispiele nur eine Breite von etwa 60 Zeichen, pprint formatiert aber auf eine Breite von 72 Zeichen. So kann der durch pprint zu erzielende Effekt ohne weitere Maßnahmen nicht gezeigt werden. Das Paket definiert aber mit *print-right-margin* eine Var, die dynamisch auf eine Breite gesetzt werden kann, so dass die Funktion von pprint auch hier sichtbar wird.
Ein gutes Hilfsmittel ist auch das Makro pp, das das letzte Resultat der REPL, das in der Var *1 vorliegt, mit pprint ausgibt.
Common Lisp format
Wenn es während der Entwicklung eines Programms notwendig ist, die Weitergabe von Argumenten durch verschiedene Ebenen von Funktionsaufrufen zu verfolgen, hilft die Bibliothek clojure.contrib.trace. Zentral ist hier das Makro dotrace, das eine Liste von zu verfolgenden Funktionen sowie einen oder mehrere Ausdrücke akzeptiert. Die genannten Funktionen werden während der Ausführung der Ausdrücke an Varianten gebunden, die sowohl ihre Eingangsargumente als auch ihren Rückgabewert ausgeben.
Das folgende Beispiel demonstriert die Verwendung von dotrace mit zwei eigenen Funktionen.
Eine Beschränkung hierbei ist, dass nicht alle Funktionen auf diese Weise verfolgbar sind. Das betrifft zum einen Funktionen, die aus Performancegründen inline ausgeführt werden, etwa die numerischen Funktionen, aber auch die Funktionen, die für dotrace verwendet werden. Offensichtlich führt das Verfolgen einer solchen Funktion zu einem Überlauf des Stacks. Ein Beispiel hierfür ist str. In der Regel wird man sich ohnehin auf die eigenen Funktionen beschränken wollen, dann fallen die Beschränkungen nicht mehr ins Gewicht.
Für die Kommunikation mit relationalen Datenbanken via SQL bietet das Paket clojure.contrib.sql vereinfachende Funktionen, die die Verwendung von JDBC kapseln. Einige der Funktionen stellen wir anhand eines Datei-Indexes vor.
Eine ganz einfache Tabelle nimmt lediglich Dateinamen auf und versieht sie mit einem eindeutigen Index:
Eine reale Anwendung wird sicherlich noch weitere Eigenschaften an dieser Stelle speichern sowie indizierte Begriffe in anderen Tabellen ablegen, für dieses Beispiel reicht diese Tabelle aber aus.
Datenbankverbindung
Inserts
Makro
Resultsets
Das SQL-Statement wird an with-query-results übergeben, das zudem einen Namen verlangt, unter dem die einzelnen Sätze angesprochen werden können.
Da sich die Dateien auf einer Festplatte gelegentlich ändern, würde im Rahmen der Wartung eine Konsistenzprüfung auf Existenz der Dateien erfolgen. Zunächst erzeugen wir dafür mit Hilfe von insert-records zwei Datensätze, zu denen es keine Dateien gibt.
Die Prüfung auf Existenz einer Datei erledigt die exists-Methode von File. Mit Hilfe von complement wird dessen Ergebnis negiert und direkt an filter übergeben.
Die Dataflow-Bibliothek ist eine geeignete Grundlage, um ein Netzwerk aus miteinander verknüpften Zellen zu erzeugen. Einigen dieser Zellen, den Quellzellen, können Werte direkt zugewiesen werden, in anderen wird der enthaltene Wert aus den als Abhängigkeit angegebenen Zellen errechnet. Dieses Netz ist inbesondere nützlich, um ein System aus voneinander abhängigen Variablen zu definieren, in dem sich die Veränderungen der Quellwerte automatisch auf ihre Abhängigkeiten übertragen.
In diesem trivialen Beispiel wird ein „Flow“ mit Hilfe des Befehls build-dataflow angelegt. In diesem Flow existieren zwei Quellzellen (width und height), die mit dem Schlüsselwort :source erzeugt werden. Ihnen können mit der Funktion update-values Werte zugewiesen werden. Zwei Validierungszellen – erzeugt mit :validator – stellen mit der weiter oben definierten Funktion not-negative? sicher, dass keiner der Werte negativ ist. Im Falle eines negativen Wertes wird, wie demonstriert, eine Exception geworfen. Die Zellen area und circumference berechnen anhand der Quellwerte den Flächeninhalt bzw. den Umfang eines Rechtecks.
Quellzellen sowie abhängige Zellen werden durch ihren Namen identifiziert und können über ihn (mit einem vorangestellten Fragezeichen) beliebig zur Berechnung von weiteren abhängigen Werten sowie in Validierungsfunktionen verwendet werden.
Der Name einer Zelle muss allerdings nicht eindeutig sein. Falls mehrere Zellen mit identischem Namen existieren, können diese mit der Syntax ?*mehrfach selektiert werden. So kann wie im folgenden Beispiel eine Berechnung in Einzelteile zerlegt werden (hier veranschaulicht als Preisnachlässe in Abhängigkeit von verschiedenen Faktoren). Dies ist allerdings nur sinnvoll, wenn letztendlich die Gesamtheit der Werte der wiederholten Zellen verwendet wird, da es aufgrund der mehrdeutigen Namen nicht mehr möglich ist, eine der Zellen explizit anzusprechen.
Der vermutlich interessanteste Aspekt ist, dass die Werte der abhängigen Zellen nicht bei jedem Zugriff (get-value) berechnet werden; vielmehr führt das Aktualisieren einer Quellzelle zur Neuberechnung der Werte in allen direkt oder indirekt beteiligten Zellen.
Insgesamt existiert bereits eine erstaunlich große Menge an Bibliotheken; alleine in Clojure selbst sowie der dazugehörigen Contrib-Sammlung sind Funktionen für diverse Anwendungszwecke vorhanden.
In einigen Fällen handelt es sich um relativ einfache Wrapper, die einen „funktionalen“ Zugriff auf bekannte Java-Schnittstellen ermöglichen; zum Beispiel die Funktionen in den Namespaces logging, swing-utils und server-socket (alle drei sind Teil der Contrib-Bibliothek).
Auf der anderen Seite gibt es von Java unabhängige Libraries, die teilweise nicht unerhebliche Komplexität aufweisen. Es ist im Rahmen dieses Buches unmöglich, auf alle einzugehen, einige der subjektiv wichtigsten sollen jedoch zumindest Erwähnung finden:
Viele weitere Bibliotheken sind auf der Seite „Clojure Libraries“ [33] oder aber auch verstreut im Internet zu finden. Die überwiegende Mehrzahl steht unter freien Lizenzen zum Download bereit, die meist auch die kommerzielle Nutzung gestatten.