Dem englischen Begriff „Concurrency“ haftet durch seinen Wortstamm die passende
Konnotation von miteinander um Ressourcen konkurrierenden Einheiten an, was den Kern des
Concurrent Programming gut beschreibt. Die Threads eines Prozesses konkurrieren um die
Ressourcen: die Daten, die der Prozess im Speicher vorhält. Clojure bietet (über die
Mechanismen von Java hinaus) kein Werkzeug, um die Veränderungen der Welt außerhalb des
eigenen Prozesses – in einem verteilten System – zu verarbeiten; Clojure konzentriert sich auf
lokale Veränderungen im eigenen Prozess, die durch verschiedene Threads entstanden sein
können.
Im November 2009 führte die TOP500 der schnellsten Computer der Welt der „Jaguar“ der
Firma Cray an, der am Oak Ridge National Laboratory unter anderem bei der Suche nach
neuen Energiequellen zum Einsatz kommt [69]. In diesem Rechner arbeiten mehr als 37 000
Prozessoren mit je sechs Kernen, also insgesamt mehr als 220 000 Prozessoreinheiten. Dabei
blickt die Firma Cray auf eine lange Geschichte von Supercomputern zurück, seit der erste
Computer dieser Firma, die Cray-1, 1976 in Betrieb genommen wurde. Die parallele
Verarbeitung in Computern ist also kein wirklich neues Phänomen, wenngleich sie sich zu
Beginn im High-End-Bereich abspielte.
Eine Aufgabe beschleunigen
Es werden zwei Arten von parallelem Arbeiten unterschieden. Zum
Ersten die Beschleunigung einer langwierigen Verarbeitung, indem Teile einer Berechnung auf
verschiedene Prozessoren verteilt werden. Deren Ergebnisse laufen dann an einer
zentralen Stelle zusammen und liefern somit das endgültige Resultat. Ein Job wird
durch Verteilung auf Recheneinheiten in seiner Gesamtheit beschleunigt. In der
Vergangenheit war diese Form weit verbreitet, und die technischen Hilfsmittel sind auf
diese Art der Parallelverarbeitung abgestimmt. Vor allem Schleifenkonstrukte lassen
sich unter bestimmten Voraussetzungen zerlegen und verteilen. Fortran hat auch
heute noch den Ruf, für diese Art von Programmierung besonders geeignet zu sein;
im C-Umfeld ist die Bibliothek OpenMP [50] von großer Bedeutung. Langwierige
Simulationen, meist in der Forschung, verlangen nach dieser Form von Parallelität, aber auch
auf den Computern von Endanwendern kann ein Programm davon profitieren. Ein
Beispiel ist ein Programm zur Bildverarbeitung, das die Berechnung eines Effekts
parallelisiert.
Mehrere Aufgaben gleichzeitig
Eine zweite Art von paralleler Verarbeitung betrifft die
gleichzeitige Verarbeitung von mehreren Aufgaben oder Jobs, die nicht gleichartig sein
müssen. Typische Anwendungsfälle sind Webserver, die gleichzeitige Besucher möglichst
schnell bedienen müssen, oder aber auch clientseitige Programme, die in der Oberfläche
noch flüssig reagieren sollen, während die Applikation im Hintergrund gerade eine
Aufgabe ausführt. Dass kann beispielsweise eine komplizierte Berechnung oder eine
Kommunikation über das Netzwerk sein. Diese Form der Parallelität gewinnt zusehends an
Bedeutung.
Beiden gemein ist, dass sie gelegentlich auf gemeinsame Ressourcen zugreifen
müssen, und das birgt Potenzial für viele Konflikte. Das vordringliche Problem ist, dass die
meisten Programmierer während der Entwicklung ihres Programms im Kopf immer noch
das Konzept einer kontrollierten Welt haben. In dieser Welt schreitet die Zeit nur
voran, wenn das Programm weiterläuft. In der Folge spiegelt sich dieses Konzept im
Programm wider. Programme gehen permanent davon aus, dass sie ihre gesamte Umwelt
kontrollieren, dass sich Dinge nicht ändern, wenn das Programm diese Änderung nicht selbst
vornimmt. Diese Annahme ist insbesondere in Bezug auf nebenläufige Prozesse nicht
korrekt.
Concurrency ist ein zentrales Thema von Clojure. Dieses Kapitel
behandelt die Eigenschaften von Clojure, die die Arbeit mit Concurrent Programming
vereinfachen. Viele Eigenschaften tragen dazu bei, dass Clojure eine interessante Sprache ist,
die zu lernen viel Spaß machen kann und die leicht produktiv einsetzbar ist. Für manche Leute
dürften Clojures Technologien, die sich mit Concurrent Programming befassen, ein
wesentlicher Grund sein, sich für Clojure und keine andere Sprache zu entscheiden. Dabei sind
es nicht die einzelnen Eigenschaften, die Clojure in diesem Bereich bedeutsam machen, es ist
deren Zusammenspiel.
Um die Lösungen von Clojure zu verstehen und sie sinnvoll einsetzen zu können, sind einige
Sätze zu den Begriffen Zustand, Identität und Wert vonnöten, die Rich Hickey auf der
Webseite von Clojure [29] ausführlich beschreibt und deren Bedeutung er als Video auf
InfoQ [32] überzeugend präsentiert.
Eine Identität in diesem Zusammenhang ist eine logische Einheit, die im Laufe der Zeit
verschiedene Zustände einnehmen kann. Ein Zustand einer Identität ist die Verknüpfung mit
einem Wert zu einem bestimmten Zeitpunkt, und ein Wert schließlich ist eine unveränderliche
Größe.
Die Zahl Elf ist die Zahl Elf. Sie ist es jetzt, sie war es gestern, und sie wird es morgen
auch noch sein. Die Zahl Elf ist unveränderlich; sie ist ein Wert. Ebenso ist der Name „Timo“
genau das: ein Name, der nicht geändert werden kann, denn dann wäre es ein anderer
Name.
Bei Zahlen und Namen entspricht diese Anschauung noch der der meisten Programmierer.
Es gilt aber, dieses Konzept auch auf zusammengesetzte Datentypen wie Listen, Vektoren oder
Maps auszuweiten. Eine Liste mit den Zahlen Eins, Zwei und Drei wird immer diese Liste
bleiben. Würde eine Vier hinzugefügt, entstünde eine neue Liste mit den Zahlen Eins, Zwei,
Drei und Vier.
Wenn aber die Anzahl der Spieler einer Fußballmannschaft gefragt ist, so
wird nach einer Identität gefragt, nach etwas mit Bedeutung. Zu einem bestimmten
Zeitpunkt entsteht dann eine Verknüpfung zwischen dieser Anzahl und der Zahl Elf.
Gleichermaßen kann nach der minimal notwendigen Anzahl der Punkte, um im Tischtennis
einen Satz zu gewinnen, gefragt sein, was ebenfalls zu einer Verknüpfung mit der Elf
führt.
Allerdings hat sich dieser Zustand – die Verknüpfung von Identität und Wert – im
Jahre 2001 geändert. Vorher war der Zustand der Identität „minimal notwendige Anzahl der
Punkte, um im Tischtennis einen Satz zu gewinnen“ eine Verknüpfung mit dem Wert 21.
Ähnliches gilt für den Namen „Timo“. Im Jahre 2009 sind die Identitäten „Vorname des
besten deutschen Tischtennisspielers“ und „Vorname des Torhüters des Fußballvereins
TSG 1899 Hoffenheim“ mit dem Wert „Timo“ verknüpft. Im Jahre 1992 war aber
wohl Jörg Roßkopf der beste deutsche Tischtennisspieler – die Verknüpfung bestand
also mit dem Wert „Jörg“ –, und die TSG 1899 Hoffenheim war in der Fußballwelt
weitgehend unbekannt, so dass sich Frage nach dem Torhüter nur wenige Menschen
stellten. (Gleichwohl war die TSG zu dieser Zeit aber schon auf dem Weg nach ganz
oben, nachdem sich der SAP-Mitbegründer Dietmar Hopp schon bei dem Verein
engagierte.)
Eine Liste von elf Namen mag der Startformation eines Fußballvereines in
einem bestimmten Spiel zugeordnet gewesen sein, vermutlich sogar mehreren Startformationen
bei verschiedenen Spielen. Bei einem anderen Spiel derselben Mannschaft hingegen, bei der ein
anderer Stürmer zu Beginn auflaufen durfte, war die Identität der Startformation
dieses Teams mit einer anderen Liste von Spielern verknüpft; ausdrücklich nicht mit
derselben Liste, in der ein Spielername durch einen anderen ersetzt wurde. Dieses
letzte Beispiel verdeutlicht, wie einfach die Modellierung der Zeit wird, wenn Werte
sich nicht im Laufe der Zeit ändern. Wollte man am Ende der Saison ein Jahrbuch
schreiben und würde auf eine sich laufend ändernde Liste von Spielern zugreifen, müsste
der gesamte Saisonverlauf erneut abgespielt werden. Spätestens bei Verweisen von
einem Spiel zu einem anderen wird das schnell unübersichtlich. Liegen hingegen die
einzelnen Werte, die Startformationen, separat vor, gestaltet sich der Zugriff einfach und
sicher.
In der oben zitierten Präsentation beleuchtet Rich Hickey anhand eines
weiteren anschaulichen Beispiels – eines Geh-Wettbewerbes – einen weiteren Aspekt: das
Vergehen von Zeit außerhalb eines Threads. Beim Gehen gilt die Regel, dass zu jedem
Zeitpunkt mindestens einer der beiden Füße den Boden berühren muss. Sind einmal beide
Füße in der Luft, gilt das als Laufen oder Rennen und wird als Foul geahndet. Eine
Implementation dieser Regel könnte wie folgt aussehen:
- Betrachte den linken Fuß.
- Ist der auf dem Boden, ist alles in Ordnung.
- Ist der in der Luft, betrachte den rechten Fuß.
- Ist der ebenfalls in der Luft, liegt ein Foul vor.
Offensichtlich sind aber das Rennen und die Bewegung des Läufers während der Messung
weitergegangen (oder -gelaufen, je nachdem), so dass wir bei der Messung des Zustands
des rechten Fußes nicht mehr voraussetzen können, dass der linke noch in der Luft
schwebt. Genau das aber ist es, was die meisten unserer Programme heute tun.
Sie nehmen an, die Welt steht still, solange sie selbst nicht weiter voranschreiten.
Was wir brauchen, ist ein Snapshot, eine Fotografie des Läufers, die beide Füße
gleichzeitig zeigt. Auf diesem Snapshot können wir dann in Ruhe die Auswertung
durchführen und somit ein eventuell vorliegendes Foul sicher feststellen. Eine Lösung ohne
Snapshot, sondern mit Locking-Mechanismen würde, übertragen auf das Beispiel, zu der
unsinnigen Notwendigkeit führen, den Läufer vor der Prüfung seines Zustands zu
bitten, er möge kurz innehalten. Speziell wenn er zu diesem Zeitpunkt gerade ein Foul
beginge, würden wir in arge Probleme mit der Physik kommen. (Natürlich hinkt der
Vergleich.)
Clojure gibt uns Werkzeuge, um Veränderungen an Identitäten im Laufe der Zeit zu
handhaben. Diese Werkzeuge und deren Grundlagen werden in den nächsten Abschnitten
beschrieben.
Wer mit Clojure erfolgreich sein möchte, muss sich dieses Gedankengut zu eigen machen
und beim Design seiner Programme beachten. Wer das nicht tut, programmiert gegen die
verwendete Programmiersprache und wird mit hoher Wahrscheinlichkeit nicht damit glücklich
werden.
Ein wesentlicher Bestandteil von Clojures Concurrency-Maschinerie sind die Datenstrukturen,
die zuvor in Abschnitt 2.6.6 eingeführt wurden. Für das schlüssige Gesamtbild von Clojure
sind zwei Eigenschaften dieser Datenstrukturen von großer Bedeutung. Zum einen
sind die gespeicherten Informationen nicht mehr zu verändern, zum anderen ist die
Implementation hinreichend geschickt, dass zu großer Overhead beim Kopieren vermieden
wird.
Datentypen in Clojure enthalten Werte. Werte sind, wie beschrieben, unveränderlich. Alle
Daten in Clojure sind somit unveränderlich, immutable. Diese Feststellung ist von zentraler
Bedeutung. Wenn ein Programm einer Liste einen Wert hinzufügen will, muss es eine neue
Liste anlegen, in der alle alten Werte und der neue Wert enthalten sind. Wenn ein
Programm zu einer zuvor gemerkten Zahl einen weiteren Wert addieren will, wird die
Addition eine neue Zahl zurückliefern. Eine Zuweisung in der Form x = x + 2 ist für
Clojures Datentypen nicht vorgesehen; für veränderliche Daten existieren spezielle
Referenztypen.
Es widerspricht der Erfahrung – vor allem der objektorientierter Programmierer –,
Zustandsinformationen nicht an vielen Stellen im Programm speichern zu sollen. Dennoch ist
diese Eigenschaft für die Verteilung von Programmarbeit auf mehrere Threads essenziell, da
auf diese Weise Nebenffekte sicher vermieden werden. Programmierer mit Erfahrungen im
Bereich der funktionalen Programmiersprachen sind mit dem Umgang mit unveränderlichen
Daten in der Regel vertraut; aber auch Java-Programmierer kennen beispielsweise
unveränderliche Strings.
Unveränderliche Datentypen sind die Grundlage für weitergehende
Technologien. Sie erlauben eine effiziente Implementation der im folgenden Abschnitt
beschriebenen persistenten Datenstrukturen. Diese wiederum sind für das Transaktionsmodell
in seiner jetzigen Form unerlässlich.
Bevor wir uns mit dem eigentlichen Inhalt dieses Abschnittes befassen, gilt es, die Verwendung
des Begriffes „persistent“ zu erklären. In den meisten Fällen bedeutet „Persistieren“ das
Speichern von Daten auf einen nichtflüchtigen Datenträger, meist eine Festplatte. Das
geschieht entweder durch eine Datenbank, die zwischen der Festplatte und dem Programm
vermittelt, oder aber direkt in Form von Dateien. Eine „persistente Datenstruktur“ hingegen
hat mit Persistenz im Sinne von dem Erhalt der Werte auch nach einem Stromausfall nichts zu
tun, sondern bezeichnet das beobachtete Verhalten, dass nach einer Manipulation
der Datenstruktur auch die vorherige Version noch vorhanden ist [19]. In diesem
Sinne sind Clojures persistente Datenstrukturen nichtflüchtig. Die von Sprachen wie
Java oder C bekannten Datenstrukturen hingegen, die eine direkte Manipulation
erlauben, sind flüchtig: Nach einer Manipulation ist die vorherige Version nicht mehr
erreichbar.
Clojures Datenstrukturen sind unveränderlich, das Hinzufügen eines Wertes zu einer Liste
von Werten erzeugt eine neue Datenstruktur. In einer naiven Umsetzung, die eine neue
Datenstruktur durch eine vollständige Kopie erzeugt, könnte das sehr viel Speicher benötigen
und die Performance spürbar negativ beeinflussen. Clojure begegnet dem Problem mit einer
effizienten Organisation von persistenten Datenstrukturen, bei der sich die Datenstrukturen
die im Speicher vorgehaltenen Werte teilen. Shared StructureWird einem Vektor mit zehn
Werten ein weiterer Wert hinzugefügt, entsteht ein Vektor, der Verknüpfungen zu den
ersten zehn Werten enthält und zusätzlich noch eine weitere Verknüpfung zum neuen
Wert. Dieses Konzept, im Englischen mit „shared structure“ bezeichnet, verlangt
nach einer effizienten Implementation und bildet dann die Grundlage dafür, dass
Datenstrukturen bei akzeptabler Performance unveränderlich sein können. Umgekehrt kann
eine solche Organisation des Speichers aber nur erfolgreich sein, wenn die referenzierten
Daten unveränderlich sind, da sonst alle Änderungen überwacht und hinsichtlich der
Verfügbarkeit für alle Verwendungen der Datenstruktur im Programm überprüft werden
müssten.
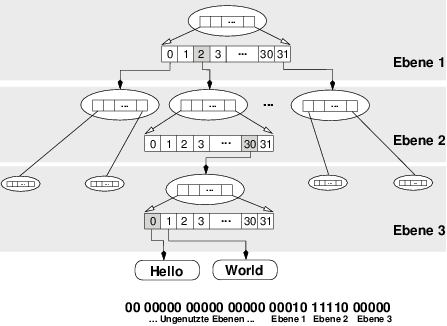
Die Organisation der Dateninhalte übernehmen sehr flache
Baum-Strukturen, die aus bis zu fünf Ebenen bestehen. In der ersten Ebene befindet sich der
Root-Knoten dieses Baums, und dieser Knoten hat Platz für 32 Objekte. Diese Objekte sind,
solange die Datenstruktur nur bis zu 32 Objekte aufnehmen muss, die zu speichernden
Dateninhalte. Beim Einfügen des 33. Wertes wird eine neue Ebene im Baum erzeugt. Dann
enthält der Root-Knoten nicht mehr 32 Verweise auf Dateninhalte, sondern auf
32 neue Knoten, die ihrerseits die zu speichernden Objekte beinhalten. In dieser
Ebene ist Platz für bis zu 32 × 32 = 1024 Objekte. Wird ein weiteres hinzugefügt,
entsteht wieder eine neue Ebene, die dann Platz für bis zu 323 = 32768 Objekte
bietet.
Wird auf ein Objekt in dieser Datenstruktur mit Hilfe seines Indexes zugegriffen,
muss Clojure im Baum den korrekten Pfad zu dem Objekt finden. Dazu macht es sich die
Eigenschaft von Java zunutze, dass Integerwerte in 32 Bit gespeichert werden. Diese 32 Bit
werden in sechs Gruppen zu je fünf Bit zerlegt, und jede Gruppe ist für den Index innerhalb
einer Ebene des Baums zuständig. Die fünf Bits kodieren genau die benötigten 32 Werte für
den Index in einem Knoten.
Das Beispiel in Abbildung 3.1 zeigt den Zugriff auf den Index 3008. In binärer Schreibweise ist
das:
300810 = 00 00000 00000 00000 00010 11110 000002
Die Tiefe des Baums ist drei, es werden also Indizes in drei Ebenen benötigt. Dabei kodieren
die niedrigstwertigen Bits die letzte Ebene im Baum: den Zugriff auf die gespeicherten Werte.
Clojure beginnt somit bei einem Baum mit drei Ebenen bei der dritten Fünfergruppe, im
Beispiel 00010, was Zahl zwei kodiert, deren Auftreten im Knoten hervorgehoben ist.
Für die zweite Ebene findet Clojure die Gruppe 11110, also den Index 30, in der
Abbildung ebenfalls hervorgehoben, und für die dritte Ebene Index 0. In der dritten
Ebene zeigt das gefundene Element schließlich auf den Dateninhalt, im Beispiel
„Hello“.
Auf diese Art und Weise kann Clojure bis zu 326 = 230 Werte in einer Datenstruktur
speichern und einen Zugriff auf persistente Datenstrukturen innerhalb von  (log 32N)
garantieren.
(log 32N)
garantieren.
Wann immer nun auf Basis einer solchen Datenstruktur eine weitere
Datenstruktur erstellt wird – sei es durch Hinzufügen weiterer Werte oder durch
Austauschen eines Wertes –, kann der größte Teil des Baums unverändert übernommen
werden. Lediglich der Teil, in dem eine Veränderung stattgefunden hat, also der Pfad
vom veränderten Wert hoch bis zum Root-Knoten, muss neu aufgebaut werden
(vgl. Abb. 3.2).
Die tatsächliche Implementation enthält kleinere Abweichungen von diesem Prinzip, die der
Verbesserung der Performance dienen. Diese bitpartitionierten Bäume liegen auch den
Hash-Maps zugrunde, wenngleich dort etwas mehr Aufwand betrieben werden muss, um
die Implementation praktikabel zu gestalten (Hash-Kollisionen, Performance und
Speicherbelegung…).
Zeit vergeht, Identitäten verändern sich. Das Ändern einer Datenstruktur an sich ist kein
Problem. Erst wenn während der Änderung ein anderer Thread auf die Daten zugreift und
durch die Bedingungen zur Laufzeit einen inkonsistenten Zustand vorfindet, ergeben sich
Fehler. Diese Art von Fehlern ist von anderer Natur als die Fehler, die bei einem
Singlethreaded-Programm auftreten. Sie sind deutlich schwerer zu reproduzieren, da sie sehr
stark vom zeitlichen Ablauf der Programmteile abhängen.
Die Informatik kennt die Probleme, die sich aus konkurrierenden Zugriffen auf geteilte
Ressourcen ergeben, seit bald 40 Jahren und hat im Laufe der Zeit drei wichtige Modelle
entwickelt und verfeinert, um dieser Probleme Herr zu werden. Der aktuelle Abschnitt stellt
diese Modelle vor, ohne jedoch zu sehr in die Tiefe zu gehen. In der Literatur finden
sich zahlreiche detaillierte Beschreibungen. Die Artikel der Wikipedia zu diesen
Themen [82][81][80] sind ein guter Anfangspunkt, von dem aus in die weitergehende
Fachliteratur eingestiegen werden kann.
Das am weitesten verbreitete Modell, um den Zugriff von verschiedenen Threads auf geteilte
Ressourcen zu koordinieren, ist Locking. Dabei wird der Zugriff auf eine Ressource kurzzeitig
während einer Änderung gesperrt, bis wieder ein Konsistenter Zustandkonsistenter
Zustand herrscht. Um das Auslesen inkonsistenter Zustände zu vermeiden, wird
unter Umständen sogar während des Lesens der Zugriff für andere Programmteile
gesperrt. Dieses Lösungsverfahren beruht historisch darauf, dass frühe Erfahrungen
mit Concurrency nur mit einer Simulation erfolgten, die tatsächlich auf nur einer
Recheneinheit stattfand. In dem Szenario erscheint eine Lösung, die einen exklusiven
Zugriff regelt, sinnvoll, da ohnehin nie ein wirklich gleichzeitiger Zugriff erfolgen
kann.
Locking ist in allen nennenswerten Programmiersprachen vorhanden, und sehr viele
Programmierer verfügen bereits über Erfahrungen damit. Zudem erlaubt es eine sehr direkte
Steuerung, da der Entwickler die Kontrolle über alle Locks hat. Doch Locking korrekt zu
implementieren, ist schwierig – vor allem unter Berücksichtigung aller möglicher
Fehlerszenarien und bei Einsatz von mehreren Prozessorkernen.
In seiner einfachsten Form wird für eine Ressource oder einen Programmteil ein
globales Lock benötigt. Das ist auch für unerfahrene Programmierer relativ leicht korrekt zu
implementieren. Allerdings leidet darunter die Performance, denn jede dieser Stellen wird zu
einem Flaschenhals, an dem keine Verteilung auf verschiedene Prozessoren möglich ist. Alle
Threads müssen durch diesen Flaschenhals, insbesondere ist auch der lesende Zugriff gesperrt,
da sich die Daten ja während einer Änderung in einem inkonsistenten Zustand befinden
können.
Man stelle sich ein Fußballspiel vor, bei dem jeder der 40 000 Zuschauer im
Stadion bei einer Torszene kurz die Welt anhält, sich das Geschehen genau betrachtet, um
festzustellen, ob der Ball hinter der Linie war, und dann für alle anderen Zuschauer zum
Anschauen freigibt. Das bedeutet, dass jeder „lesende“ Zugriff seine eigene Zeitlupe ablaufen
lässt. Seriell. In Wirklichkeit läuft das Spiel jedoch weiter, und jeder Zuschauer kann es
betrachten. Übertragen auf die Programmierung heißt das: Lesender Zugriff sollte
nicht sperrend erfolgen. Die Übertragung im Fernsehen lässt das Spiel weiterlaufen,
zeigt aber wenigstens für alle „Leser“ gemeinsam einen Snapshot der Situation: die
Zeitlupen-Einspielung. Das entspricht ungefähr dem Verhalten von Clojure, mit
dem Unterschied, dass in Clojure die schreibenden Zugriffe ihre eigene kleine Welt
erhalten.
Performance und Komplexität durch mehr Locks
Wenn ein globales Lock mehrere Identitäten
schützt, so kann die Performance deutlich steigen, wenn die einzelnen Identitäten dedizierte
Locks erhalten. Mit diesem Verfahren ist es möglich, den Zugriff granularer zu steuern und
auch deutlich mehr lesende Zugriffe zu gewähren, während andere Programmteile die Daten
verändern. Allerdings ist es auch deutlich schwieriger, diese Locks zu koordinieren. Das richtige
LockEine ganz einfache Folge von mehr Locks ist, dass die Programmierer sich merken
müssen, welches Lock für welche Ressource gilt. Es klingt banal, aber im Alltag kommt
es vor, dass Programmabschnitte ein falsches Lock verwenden, dessen Aufgabe es
ist, ganz andere Daten zu schützen. Sicherzustellen, dass ein Lock nur einmal pro
Programmabschnitt verwendet wird, wird ebenfalls schwieriger. Der englische Begriff hierfür
ist Reentrancy„Reentrancy“. Insbesondere bei rekursiven Lösungen, aber auch bei anderen
Abläufen, die auf verschiedenen Ebenen des Stacks Locks benötigen, taucht dieses
Problem auf. DeadlockUnd als Abschluss dieser Liste die Folge von Locks, die in
der falschen Reihenfolge akquiriert werden. Was geschieht, wenn ein Programmteil
die Locks „A“ und „B“ braucht, „A“ bereits hat und auf „B“ wartet, während ein
anderer Programmteil ebenfalls diese beiden braucht, „B“ hat und auf „A“ wartet?
Nichts mehr, es liegt ein Deadlock vor. In dieser Beschreibung klingt das natürlich
trivial, aber in der Realität der Programmierung kommt es vor und ist dabei oft gut
versteckt.
Ein weiterer Aspekt ist, dass Sperrverfahren mit Locking pessimistisch sind. Sie
gehen davon aus, dass nur genau ein Programmteil, der Zugriff auf einen Satz von Daten
benötigt, zur gleichen Zeit laufen kann. Daher blockieren sie eventuelle Aktionen auf den
Ressourcen vor deren Ausführung. Diese Annahme ist aber nicht notwendigerweise richtig:
Etwa wenn zwei verschiedene Programmteile zwar auf den gleichen Vektor zugreifen müssen,
aber jeder Teil mit einem anderen Index. Oder wenn ein Programmteil schreiben und ein
anderer lesen will, wobei der letztgenannte auch mit „etwas älteren“ Daten zufrieden
ist.
Korrektes Concurrent Programming mit Locks ist möglich, aber schwierig in der
Umsetzung. Da Javas Technologien für Concurrency in Clojure verwendet werden können,
stehen somit auch Locks in Clojure zur Verfügung.
Eine alternative Möglichkeit für die Kontrolle des Zugriffs auf eine geteilte Ressource ist das
Aktoren-Modell, das beispielsweise in der Programmiersprache Erlang [4] eine zentrale Rolle
spielt. Wesentlich für dieses Modell ist, dass die zahlreichen Programmeinheiten
keine Ressourcen miteinander teilen, sondern sich die jeweiligen Daten zusenden.
Ein Aktor ist eine Einheit, die Nachrichten empfangen und darauf entweder durch
Versenden neuer Nachrichten an andere Aktoren, durch Veränderung seines internen
Zustands oder auch durch Erzeugen weiterer Aktoren reagieren kann. Eine solche
Einheit kann durch einen Prozess, einen Thread oder etwas Vergleichbares dargestellt
sein. Alle Reaktionen können dabei in beliebiger Reihenfolge oder auch parallel
erfolgen.
In den letzten Jahren haben Webservices einen gewissen Boom
erlebt. In solchen Szenarien können die Endpunkte eines Webservice durchaus als
Aktoren im Sinne des hier vorgestellten Modells verstanden werden. Wer mit solchen
Services bereits Erfahrungen gesammelt hat, ist möglicherweise auch schon mit einer
Einschränkung des Aktoren-Modells in Berührung gekommen. Wenn die zu versendenden
Nachrichten sehr groß werden, beispielsweise weil sie eine große zu bearbeitende
Datenmenge enthalten, leidet einerseits die Performance, andererseits steigt meist
auch der Speicherbedarf stark an. Ein weiteres Problem ergibt sich daraus, dass der
Datenbestand eines Aktoren inkonsistent zu den Daten anderer Aktoren geworden sein
kann.
Koordination von Datenpaketen
Wer heute eine Webseite besucht, bekommt ein Dokument
ausgeliefert, das aus vielen einzelnen Bestandteilen zusammengesetzt ist. Der Browser schickt
dabei für jeden Bestandteil eine separate Anfrage ab. Die Reihenfolge, in der die Antworten
erfolgen, ist dabei ebenso wenig festgelegt wie im darunter liegenden Netzwerkprotokoll die
Reihenfolge des Eintreffens einzelner Datenpakete. Auch dieses Szenario lässt sich mit einem
Aktoren-Modell beschreiben. Da aber weder die Reihenfolge, in der die Aktoren ihre Daten
versenden, noch deren Konsistenz durch ein Handshake-Verfahren sichergestellt sind, müssen
geeignete Prozesse des gesamten Szenarios für das Zusammenfügen sorgen und die Konsistenz
sicherstellen. Wenn zusätzlich betrachtet wird, dass ein Aktor nicht nur Nachrichten an andere
Aktoren senden kann, deren Adressen er bereits kennt, sondern sowohl neue Aktoren erzeugen
als auch die Adressen von weiteren Aktoren in der Nachricht übermittelt bekommen
kann, ergibt sich schnell eine hohe Komplexität. Diese kann sich auch in Deadlocks
äußern.
Prozess- und systemübergreifend
Da Aktoren aber nicht auf gemeinsame Ressourcen zugreifen,
erlauben sie auch eine nichtlokale Concurrency über Maschinen- und Netzwerkgrenzen hinweg.
Das rechtfertigt die erhöhte Komplexität, die mit diesem Modell einhergeht. Das
Aktoren-Modell ist eine interessante Herangehensweise, die jedoch in populären
Programmiersprachen kaum vorhanden ist. Scala, Haskell und natürlich Erlang sind
vermutlich die bekanntesten Vertreter. Clojure unterstützt das Aktoren-Modell nicht,
wenngleich es einige Bibliotheken gibt, die dieses Modell in Java verfügbar machen, etwa
JavaAct [3] und ActorFoundry [39].
Datenbanken koordinieren seit langer Zeit konkurrierende Zugriffe auf die in ihnen
gespeicherten Daten. Das Mittel der Wahl sind dort Transaktionen, deren wichtigste
Eigenschaft es ist, dass sie entweder ganz oder gar nicht stattfinden. Im Datenbankumfeld ist
dieses Verfahren erprobt, und der Gedanke liegt nahe, diese Technologie auf Daten im
Speicherbereich eines Programms anzuwenden. Transaktionen in einer Datenbank weisen vier
wichtige Eigenschaften auf:
-
A
- Sie sind atomar (atomic), das heißt, egal wie viele Daten in einer Transaktion
manipuliert werden, von außen betrachtet erfolgen alle Änderungen, wenn
überhaupt, dann in einem einzigen Schritt.
-
C
- Sie sind konsistent (consistent). Die Daten, die eine Transaktion selbst zu Gesicht
bekommt, befinden sich ebenfalls in einem konsistenten Zustand, sowohl am Start
der Transaktion als auch am Ende.
-
I
- Sie sind isoliert (isolated). Änderungen, die innerhalb einer Transaktion an den Daten
erfolgen, sind nicht von außen sichtbar, bevor die Transaktion nicht (erfolgreich)
beendet wird.
-
D
- Sie sind dauerhaft (durable), das heißt, wenn eine Transaktion erfolgreich beendet
wurde, sind die Daten auf ein Medium (die Festplatte) gesichert, das eine Störung
in Form von Software- oder Hardwarefehlern übersteht.
Von diesen wichtigen Eigenschaften lassen sich die ersten drei auch auf Manipulationen
flüchtigen Speichers übertragen, lediglich die Sicherung auf nichtflüchtige Medien entfällt.
Ausgehend in den 1980er-Jahren von der (patentierten) Idee, transaktionalen Speicher zu
bauen, konzentrieren sich Forschung und Entwicklung seitdem auf reine Softwarelösungen:
Software Transactional Memory oder kurz STM.
Das Verfahren basiert auf einer Transaktionsmaschinerie, die gleichzeitigen Transaktionen
jeweils einen eigenen Zugriff auf die zu manipulierenden Daten gewährt, alle agieren lässt und
erst, wenn eine Transaktion signalisiert, dass sie fertig ist, entscheidet, was zu tun ist.
CommitDen abschließenden Schritt, der die Manipulation der Daten einer Transaktion auch für
andere Programmteile manifestiert, nennt man Commit. Diesen Abschluss kann von
gleichzeitigen Transaktionen nur eine durchführen: diejenige, die zuerst ihren Commit
versucht. Alle anderen müssen in der Regel ihre Arbeit erneut beginnen. Wiederholungen: Keine
NebeneffekteDiese Wiederholungen stellen eine wichtige Anforderung an die Funktionen, die in
einer Transaktion durchgeführt werden: Sie dürfen keine Effekte haben, die nicht
zurücksetzbar sind. Meist bedeutet das, dass sie keine Nebeneffekte haben dürfen. Reine
Funktionen erfüllen diese Anforderung.
STM hat zwei wichtige Vorteile. Erstens ist es, im Gegensatz zum
Locking, ein optimistischer Ansatz. Lesende Zugriffe werden nicht blockiert, auch alle
schreibenden Zugriffe werden, wenn das Transaktionssystem nicht vorher mögliche
Konflikte erkennen kann, bis zur Commit-Phase durchgeführt. Das erlaubt einen
höheren Grad an Parallelisierung. Der zweite Vorteil ist, dass dieses Modell ebenso
einfach zu verstehen wie einfach in der Handhabung ist. Der Programmierer muss
eigentlich nur darauf achten, dass die in einer Transaktion verwendeten Funktionen keine
Nebeneffekte haben, und den Rest erledigt das Transaktionssystem. Implementation mit
LockingDie konkrete Implementation des Transaktionssystems kann mit Hilfe von Locking
erfolgen. In dem Falle müssen aber nur die Entwickler dieses Systems das Locking in
den Griff bekommen, alle weiteren Anwender des Transaktionssystems sind davon
befreit.
Nachteilig an STM sind die höheren Anforderungen an Speicher und CPU. Jede
Transaktion braucht genau genommen eine komplette Kopie der zu verändernden Daten, und
die möglichen Wiederholungen verbrauchen mehr Rechenleistung. Bei n gleichzeitigen
Transaktionen kann es im schlimmsten Falle zum n-fachen Bedarf an Speicher und
Rechenleistung kommen. Zudem leidet die Vorhersagbarkeit, da der Ablauf der Transaktionen
vom Laufzeitverhalten abhängt.
STM wird derzeit intensiv erforscht und diskutiert. Dan Grossman vergleicht
die Argumente dieser Diskussion in seinem Artikel The Transactional Memory/Garbage
Collection Analogy [23] mit den Argumenten, die in den Anfängen der Garbage
Collection ins Feld geführt wurden, und beobachtet dabei deutliche Analogien. Heute
hat sich Garbage Collection als selbstverständlich durchgesetzt und ist wichtiger
Bestandteil beispielsweise der JVM. Es bleibt abzuwarten, ob auch STM sich in der
Form durchsetzen können wird. Viele Artikel, die sich zu diesem Thema im Internet
finden, haben einen optimistischen, enthusiastischen Ton. Sehr interessant ist auch
der Artikel, der die Probleme bei der Entwicklung eines STM-Systems für .NET
beleuchtet [14], die letztlich dazu geführt haben, dass Microsoft diese Entwicklung –
zumindest vorläufig – eingestellt hat. Hier wird deutlich, wie wichtig das Zusammenspiel
verschiedener Spracheigenschaften ist [37], und wie schwierig es ist, STM im Nachhinein
einzubauen.
Clojure lädt dazu ein, sich genau zu überlegen, an welchen Stellen es sinnvoll ist, Zustände zu
speichern. Alleine das kann schon helfen, robustere Programme zu schreiben, die sich besser
auf mehrere Prozessoren verteilen lassen. Dennoch bleibt die Notwendigkeit, die
Veränderung mancher Identitäten über die Zeit zu verwalten. Es ist notwendig,
das Fortschreiten der Zeit außerhalb eines Threads zu modellieren. Das Mittel zur
Lösung sind hier indirekte Referenzen. Es ist gängige Praxis, dass ein Programm
Referenzen auf die Daten hält. In Clojure sind diese aber vor Konflikten durch das
Fortschreiten der Zeit, also Manipulation durch andere Programmteile, durch ihre
Unveränderlichkeit geschützt. Um eine Identität mit einem Zustand zu versehen, erzeugt der
Programmierer eine weitere Referenz auf einen beliebigen Datentyp aus Clojures
Ensemble.
Abbildung 3.3 zeigt, wie sich indirekte Referenzen vorteilhaft auf ein Programm auswirken
können. Im linken Teil der Abbildung ist dargestellt, wie üblicherweise mit gespeicherten
Daten vorgegangen wird. Das Programm hält eine Referenz auf einen Block, in dem sich die
Daten, im Beispiel die Namen von Mitgliedern der Lisp-Sprachenfamilie, befinden. Ob dieser
Block ein Speicherbereich und die Referenz ein Zeiger, wie in C, oder aber der Block ein
Objekt ist, spielt dabei keine Rolle. Wichtig ist, sich zu verdeutlichen, dass es keinen
einfachen und direkten Weg gibt, diese Daten atomar, also in einem einzigen Schritt, zu
verändern. Das gilt nicht nur für zusammengesetzte Datenstrukturen; schon das
Verändern des primitiven Datentyps long in Java ist nicht unbedingt ein atomarer
Vorgang.
Änderungen durch Umhängen
Wenn das Programm in diesem Datensatz die Schreibweise des in
Emacs verwendeten Lisp-Dialektes von „ELisp“ zu „Elisp“ ändern und „arc“ zu der Liste
hinzufügen will, wie im rechten Teil der Abbildung gezeigt, so muss es sicherstellen, dass
Threads, die sich gerade in anderen Programmteilen befinden, jederzeit einen konsistenten
Zustand vorfinden. In der Regel wird dazu ein Lock erzeugt werden, der auch lesende
Zugriffe blockiert und nach erfolgreichem Anwenden aller Änderungen wieder entfernt
wird. Indirekte Referenzen erlauben einen deutlich einfacheren Zugriff. Hier hält das
Programm keine direkte Referenz auf den Datenblock mehr, sondern auf ein Objekt, das
davor sitzt. Benötigt ein Programmteil den Wert, muss es die gehaltene Referenz
dereferenzieren. Sollen aber die gespeicherten Daten verändert werden, kann im
Hintergrund und für andere Programmteile unsichtbar die neue Datenstruktur aufgebaut
werden bis schließlich die Referenz in einem einzigen Schritt, atomar, umgehängt
wird.
Clojure implementiert vier Referenztypen mit unterschiedlichen Eigenschaften, die sich damit
für verschiedene Anwendungsfälle empfehlen:
Allen ist gemein, dass die durch sie referenzierten Daten veränderlich sind. Wie im
Abschnitt über indirekte Referenzen (3.3.2) beschrieben, verändern sich dabei aber
nicht die Daten selbst, es wird lediglich eine Referenz von einem Wert auf einen
anderen umgehängt. Als referenzierte Information sind Clojures unveränderliche
Datentypen vorgesehen, Java-Objekte sind für diesen Einsatz in der Regel nicht
geeignet.
Wir verwenden in diesem Text durchgehend die englischen Bezeichnungen, da wir diese als
Fachbegriffe betrachten. Im Folgenden werden wir zunächst diese Typen beschreiben, um dann
abschließend eine zusammenfassende Betrachtung und einen Vergleich dieser Typen zu
liefern.
Die bereits in Abschnitt 2.7.1 beschriebenen Vars sind ebenfalls Referenztypen und haben ein
definiertes Verhalten im Multithreading-Kontext. Sie unterscheiden sich jedoch von den noch
vorzustellenden drei anderen Typen. So werden sie nicht explizit dereferenziert, und
Änderungen des enthaltenen Wertes gelten immer nur lokal pro Thread, sind also nicht in
anderen Threads sichtbar. Damit entfällt die Notwendigkeit der Koordination konkurrierender
Zugriffe. Beispielhaft wurde das Verhalten von Vars im Kontext mehrerer Threads im
Abschnitt 2.7.4 beschrieben.
Clojure stellt mit dem Typ Atom einen Referenztypen bereit, der einen beliebigen
Datentyp aus Clojures Portfolio aufnehmen kann. Dafür verwendet es unter der
Haube eine AtomicReference aus java.util.concurrent.atomic. Zur Erzeugung
eines Atom dient die Funktion atom, die den zu referenzierenden Wert als Argument
erwartet:
Der Zugriff auf den referenzierten Wert erfolgt durch Dereferenzieren mit der
Funktion deref oder der entsprechenden Read-Syntax @. Ein Atom bekommt durch
Anwendung einer der drei Funktionen reset!, compare-and-set! oder swap!, die alle durch
ihr angehängtes Ausrufezeichen den verändernden Charakter andeuten, einen neuen Wert
zugewiesen. Die einfachste Form ist reset!, die schlicht einen neuen Wert ohne weitere
Umstände zuweist:
Das folgende Beispiel zeigt die Verwendung von reset!. Es legt ein Atom an, dereferenziert
es mit deref, setzt den Wert neu und zeigt den neuen Wert durch Dereferenzieren mit der
Read-Syntax.
user> (def atm (atom "physikalische Atmosphäre"))
#’user/atm
user> (deref atm)
"physikalische Atmosphäre"
user> (reset! atm "Pascal")
"Pascal"
user> @atm
"Pascal"
Das direkte Setzen eines neuen Wertes gilt generell als nicht idiomatisch.
Im Normalfalle dürfte der neue Wert durch den Aufruf einer Funktion berechnet worden sein.
Dann aber kann diese Funktion gleich verwendet werden und der Zwischenschritt über den
gespeicherten neuen Wert entfallen. Um ein Atom auf funktionale Art mit einem neuen Wert
zu versehen, wird die Funktion swap! verwendet, die das Atom und eine Update-Funktion als
Argumente erwartet. Argumente für die Update-Funktion können ebenfalls übergeben
werden:
(swap! atom update-fn args*)
Die Update-Funktion wird mit dem aktuellen Wert des Atom und den
optionalen weiteren Argumenten, die an swap! übergeben wurden, aufgerufen. Ihr
Rückgabewert bestimmt den neuen Wert, den das Atom danach referenziert. Im Hintergrund
wird Clojure die Update-Funktion aufrufen und ihren Rückgabewert nur dann dem Atom
zuweisen, wenn in der Zwischenzeit kein anderer Thread eine Zuweisung vorgenommen hat. Im
Konfliktfall wird die Update-Funktion erneut ausgeführt. Daraus ergibt sich die
wichtige Anforderung, dass es sich um eine Funktion ohne Nebeneffekte handeln
sollte.
(def koffer
(atom
"Ich packe meinen Koffer und nehme mit: "))
user> @koffer
"Ich packe meinen Koffer und nehme mit: "
(defn packe-ein-thread [ding sleep]
(.start
(Thread.
(fn []
(Thread/sleep sleep)
(swap! koffer str ding ", ")))))
(defn koffer-packen []
(packe-ein-thread "Sammeltasse" 2000)
(packe-ein-thread "Kulturbeutel" 1500)
(packe-ein-thread "Zappaplatte" 1000)
(packe-ein-thread "Schweinehälfte" 500)
(packe-ein-thread "Klopfsauger" 100))
user> (koffer-packen)
nil
user> @koffer
"Ich packe meinen Koffer und nehme mit: Klopfsauger,
Schweinehälfte, Zappaplatte, Kulturbeutel, Sammeltasse, "
In diesem Beispiel spielt sich das Entscheidende in der Funktion packe-ein-thread ab, in
der der Aufruf von swap! an einen neuen Thread mit einer variablen Verzögerung delegiert
wird. Die Update-Funktion ist in diesem Falle die Funktion str, die die ihr übergebenen
Strings zusammenfügt. Da die Update-Funktion als erstes Argument den aktuellen Wert des
Atom bekommt und als weitere Argumente die, die an swap! übergeben wurden,
bewirkt dieser Ausdruck letztlich, dass an den String im Atom koffer verschiedene
Strings angehängt werden. Somit liest sich der Ausdruck mit swap! im Einzelnen wie
folgt:
- swap! ändert den Wert eines Atom,
- koffer ist das zu ändernde Atom,
- str ist die Update-Funktion, der swap! als erstes Argument den aktuellen Wert
übergibt, und
- ding sowie ", " sind weitere Argumente, die alle an die Update-Funktion
übergeben werden.
Also wird str unter der Haube in der Form
(str akt-im-koffer ding ", ")
aufgerufen, so dass ding an den aktuellen Kofferinhalt angehängt wird.
Die Funktion koffer-packen konzertiert das ganze Szenario und ruft die Thread-erzeugende
Funktion packe-ein-thread mit den einzupackenden Dingen und verschiedenen
Verzögerungen auf. Die Manipulation in den Threads erfolgt atomar, es kann also keine
Konflikte beim Zugriff aus verschiedenen Threads geben. Zudem finden lesende Zugriffe,
die das Beispiel nicht explizit demonstriert, jederzeit einen konsistenten Zustand
vor.
Zählen der Wiederholungen
Ein einfaches Beispiel, das zwei Atoms verwendet, kann zeigen, wie
die Update-Funktion mehrfach aufgerufen wird. Dazu wird in der Update-Funktion als
Nebeneffekt ein Atom, das als Zähler für die Aufrufe fungiert, hochgezählt, es sind also zwei
geschachtelte Atom-Aktualisierungen im Spiel.
(def countdown (atom 1000))
(def aufrufe (atom 0))
(defn tick [akt-wert]
(swap! aufrufe inc)
(dec akt-wert))
user> (dotimes [_ 1000]
(.start
(Thread.
#(swap! countdown tick))))
nil
user> @countdown
0
user> @aufrufe
1076
Das Atom countdown dient als primäres Atom, dessen Veränderungen untersucht werden
sollen, während aufrufe einen Zähler für die Aufrufe bereitstellt. Die Funktion
tick simuliert das Ticken des Countdowns und liefert den aktuellen Wert um eins
verringert zurück. Vorher jedoch erhöht sie den Wert des Aufrufzählers. Erfolgreiche
Änderungen an countdown führen also zum Runterzählen des Countdowns und
zum Hochzählen des Aufrufzählers, während nicht erfolgreiche Durchläufe nur den
Aufrufzähler erhöhen. Die Iteration mit dotimes startet die tick-Funktion jeweils in
einem neuen Thread. Nach Ablauf dieser Schleife enthält countdown wie zu erwarten
den Wert 0, es gab also exakt 1000 erfolgreiche Läufe, der Aufrufzähler aufrufe
hingegen zeigt, dass 76 Kollisionen beim Verändern zu einer Wiederholung geführt
haben.
Die letzte Funktion für die Manipulation von Atoms, die hier
vorgestellt wird, ist compare-and-set!. Ihr Einsatzgebiet liegt immer dort, wo der Wert des
Atom zu einem früheren Zeitpunkt gelesen wurde und ein neuer Wert nur gesetzt werden soll,
wenn in der Zwischenzeit keine Änderung durch einen anderen Programmteil vorgenommen
wurde. Diese Funktion wird selten direkt verwendet, bildet aber die Grundlage der
swap!-Funktion. Der Aufruf von compare-and-set! verlangt das Atom selbst, den alten sowie
den potenziellen neuen Wert:
(compare-and-set! atom wert-alt wert-neu)
Das folgende – etwas konstruierte – Beispiel zeigt einen sehr eigenwilligen
Generator für Lottozahlen, der darauf setzt, dass die jeweilige Zahl schon beim
Auswahlverfahren das Glück hatte, sich gegen andere Zahlen durchzusetzen. (Durchaus
denkbar, dass das Glücksspielfieber solche Stilblüten treibt. Sollten diese Zahlen zu einem
nennenswerten Gewinn führen, bitten wir um eine Spende an Rich Hickey für die
weitere Entwicklung von Clojure.) Im folgenden Beispiel wurde die Ausgabe deutlich
gekürzt.
(def lotto-tipp (atom []))
(defn weitere-lotto-zahl []
(let [z (+ 1 (rand-int 49))
bislang @lotto-tipp]
(Thread/sleep (rand-int 200))
(when (< (count bislang) 6)
(println "evtl kommt" z "dazu"
(compare-and-set! lotto-tipp
bislang
(conj bislang z))))))
(defn lotto-generator []
(while (< (count @lotto-tipp) 6)
(.start (Thread. weitere-lotto-zahl))))
user> @lotto-tipp
[]
user> (lotto-generator)
;; Ausgabge gekuerzt und zwei Ausgaben pro Zeile
evtl kommt 40 dazu true evtl kommt 25 dazu true
evtl kommt 7 dazu true evtl kommt 37 dazu false
evtl kommt 23 dazu false evtl kommt 8 dazu false
evtl kommt 8 dazu false evtl kommt 3 dazu false
evtl kommt 35 dazu true evtl kommt 21 dazu false
evtl kommt 3 dazu false evtl kommt 49 dazu false
evtl kommt 21 dazu true evtl kommt 44 dazu false
evtl kommt 16 dazu true evtl kommt 15 dazu false
evtl kommt 30 dazu false
user> @lotto-tipp
[40 25 7 35 21 16]
Abschnitt 3.4.5 beschreibt, wie eine Funktion eingesetzt werden kann, die
kontrolliert, welche Werte in ein Atom gespeichert werden können.
Wenn es darum geht, mehrere Werte koordiniert zu verändern, kommt mit der Ref ein
weiterer Referenztyp ins Spiel. Ein klassisches Beispiel ist eine Überweisung bei einer
Bank, bei der ein Betrag von einem Konto abgehoben und einem anderen Konto
gutgeschrieben wird. (In der Praxis scheint dieses häufig verwendete Beispiel zumindest
aus Sicht der Bankkunden wenig relevant, tauchen doch die überwiesenen Beträge
teilweise mit mehreren Tagen Verspätung erst auf dem Zielkonto auf. Wir Kunden lesen
also sehr wohl einen Zustand, in dem das Geld vom Quellkonto verschwunden und
auf dem Zielkonto noch nicht angekommen ist.) Refs werden mit der Funktion ref
angelegt, die – wie im Falle eines Atom auch – den zu referenzierenden Wert übergeben
bekommt:
Hinter den Refs arbeitet eine STM-Maschinerie, die konkurrierende Zugriffe durch ein
Transaktionssystem schützt. Schreibende Zugriffe auf eine Sammlung von Refs müssen
innerhalb einer Transaktion erfolgen. Lesende Zugriffe, die nie blockiert werden, können in
einer Transaktion erfolgen. Lesen mit oder ohne TransaktionWenn aus einem Ensemble von Refs
für einen Leseprozess nur ein Wert relevant ist, kann dessen Ref direkt dereferenziert
werden. Sind hingegen mehrere Refs von Interesse, sollte auch der lesende Zugriff in
einer Transaktion erfolgen, damit die Konsistenz des Gesamtzustands gewährleistet
ist.
Die Syntax für Transaktionen ist denkbar einfach und besteht allein in der Funktion
dosync:
Funktionen zur Manipulation
Alle Ausdrücke, die innerhalb des Rumpfes von dosync
stehen, werden in einer Transaktion ausgeführt. An dieser Stelle, und nur hier, können
dann die Funktionen zur Manipulation von Refs verwendet werden: ref-set für
die direkte Wertzuweisung, alter und commute für den bevorzugten, funktionalen
Zugriff.
user> (def eine-ref (ref 1))
#’user/eine-ref
user> (ref-set eine-ref 2)
java.lang.IllegalStateException: No transaction running
user> (dosync (ref-set eine-ref 2))
2
user> (dosync (alter eine-ref inc))
3
user> @eine-ref
3
user> (dosync (alter eine-ref + 5))
8
user> @eine-ref
8
Bei nur einer Ref verhält sich die Manipulation nicht anders als bei Atoms auch.
Der direkte Zugriff mit ref-set erwartet als Argument die Ref sowie den neuen
Wert:
(ref-set die-ref wert-neu)
Auch für Refs wird die Manipulation durch eine Funktion bevorzugt. Der
funktionale Zugriff braucht eine Funktion ohne Nebeneffekte und kann weitere Argumente für
die Update-Funktion entgegennehmen, formal:
(alter die-ref update-fn args*)
Dabei unterscheiden sich alter und commute nicht in ihrer Signatur.
Interessant wird es erst, wenn die STM-Maschinerie etwas mehr Arbeit in Form von
mehreren zu koordinierenden Refs bekommt. Im Folgenden demonstriert dies ein
Beispiel, das zwei Refs von einem Thread aus einige Male liest und von einem anderen
schreibt.
(def ref1 (ref 1))
(def ref2 (ref 1))
(defn lesethread []
(println "Thread 1: lese")
(dotimes [i 6]
(Thread/sleep 100)
(dosync
(println "T1, ref1: " @ref1 " ref2: " @ref2))))
(defn schreibthread []
(println "Thread 2: schreibe")
(dosync
(alter ref1 inc)
(Thread/sleep 300)
(alter ref2 inc)))
user> (do (.start (Thread. lesethread))
(.start (Thread. schreibthread)))
Thread 1: lese
Thread 2: schreibe
T1, ref1: 1 ref2: 1
T1, ref1: 1 ref2: 1
T1, ref1: 1 ref2: 1
T1, ref1: 2 ref2: 2
T1, ref1: 2 ref2: 2
T1, ref1: 2 ref2: 2
Dieses Beispiel ähnelt dem in Abschnitt 2.7.4, in dem das dynamische Verhalten
von Vars demonstriert wurde. Nach drei Lesevorgängen wechseln beide Refs ihren
Wert vom ersten Thread aus betrachtet gleichzeitig von 1 zu 2. Dieses Verhalten ist
sicher, und beliebig viele Ausführungen werden nie einen inkonsistenten Zustand
lesen.
An einem etwas ausführlicheren Beispiel zeigen wir die Verwendung von alter und starten
auch hier einen separaten, immer wieder lesenden Thread. Zunächst die Anlage der
Refs:
(def ref1 (ref "Original 1"))
(def ref2 (ref "Original 2"))
user> [@ref1 @ref2]
["Original 1" "Original 2"]
Des Weiteren definieren wir drei Hilfsfunktionen, die Lesen, Schreiben und die
Erzeugung eines neuen Wertes erledigen. Dabei ist die letztgenannte (namenator) mit einem
Nebeneffekt – einer Ausgabe mit println – versehen. Das ist im Normalfall nicht ratsam, da
diese Funktion als Update-Funktion für die Refs verwendet wird, und Update-Funktionen
können durch die STM-Maschinerie wiederholt aufgerufen werden. Update-Funktionen sollten
frei von Nebeneffekten sein.
(defn leserich
"Liest die aktuellen Werte"
[] (dotimes [i 10]
(dosync
(println "LESERICH" @ref1 @ref2)
(flush))
(Thread/sleep 20)))
(defn namenator
"Liefert einen Namen. Mit unklugem Nebeneffekt"
[num nam] (let [result (str "NEU" num ": " nam)]
(println "NAMENATOR" result)
result))
(defn schreiberling
"Schreibt NAM in ref1 und ref2"
[nam] (dosync
(alter ref1
(fn [_] (namenator 1 nam)))
(Thread/sleep 88)
(alter ref2
(fn [_] (namenator 2 nam)))))
Abschließend sorgt ein Aufruf von do am REPL-Prompt dafür, dass die Hilfsfunktionen mit
verschiedenen Werten in eigenen Threads aufgerufen werden. Die Sleep-Zeiten der Threads
sind so aufeinander abgestimmt, dass die Ausgabe möglichst lesbar bleibt und die Effekte der
STM-Maschinerie sichtbar werden.
user> (do (.start (Thread. leserich))
(dotimes [i 3]
(.start (Thread.
(fn []
(schreiberling (+ i 10))))))
(Thread/sleep 2000))
LESERICH Original 1 Original 2
NAMENATOR NEU1: 10
NAMENATOR NEU1: 11
NAMENATOR NEU1: 12
LESERICH Original 1 Original 2
LESERICH Original 1 Original 2
NAMENATOR NEU2: 10
NAMENATOR NEU1: 11
NAMENATOR NEU1: 12
LESERICH NEU1: 10 NEU2: 10
LESERICH NEU1: 10 NEU2: 10
LESERICH NEU1: 10 NEU2: 10
NAMENATOR NEU2: 11
NAMENATOR NEU1: 12
LESERICH NEU1: 11 NEU2: 11
LESERICH NEU1: 11 NEU2: 11
NAMENATOR NEU2: 12
LESERICH NEU1: 12 NEU2: 12
LESERICH NEU1: 12 NEU2: 12
nil
Ein Studium der Ausgabe, die durch das Multithreading bei jedem Durchlauf anders
aussehen kann, zeigt, wie der STM-Mechanismus Update-Funktionen wiederholt, da eine Ref
in der Zwischenzeit verändert wurde. Zunächst wird die Update-Funktion dreimal für die erste
Ref aufgerufen, dann einmal für die zweite, und der Schreibzugriff, der diesen Aufruf initiiert
hat, kann seine Transaktion erfolgreich beenden. Danach haben beide Refs den Wert „NEUx:
10“. Die Transaktionen, die die Zahlen 11 und 12 verwenden wollten, müssen von vorne
beginnen und rufen die Update-Funktion erneut für die erste Ref auf. Dieses Mal
bekommt der Thread mit der 11 den Zuschlag, weil er als Erster bis zum Ende seiner
Transaktion kam, und die noch verbleibende Transaktion („12“) muss von vorne
beginnen.
Es ist eine wesentliche Eigenschaft von Clojures STM-Maschine, dass
lesende Zugriffe schreibende Zugriffe nicht blockieren. Wenn eine Transaktion den Wert einer
Ref nur liest, hält das eine andere Transaktion nicht davon ab, diese Ref auf einen neuen Wert
zu setzen. Sollte jedoch gerade dieses Verhalten gewünscht sein, kann beim Lesen
des Werts die Funktion ensure anstelle von deref verwendet werden. Der Aufruf
von ensure bewirkt, dass die betroffene Ref für andere Transaktionen nicht mehr
schreibbar ist, bis die Transaktion, die ensure aufgerufen hat, beendet wurde. Solange
werden die schreibenden Transaktionen an ihrem Commit gehindert und wiederholt.
Das folgende Beispiel demonstriert zunächst das Verhalten einer Funktion, die nur
dereferenziert:
(def rohling (ref "leer"))
(defn lese-rohling []
(dosync
(let [v @rohling]
(println "lesen1" v)
(Thread/sleep 2000)
(println "lesen2" @rohling v))))
(defn brennen []
(dosync
(println "brennen" @rohling)
(Thread/sleep 600)
(alter rohling (constantly "gebrannt"))))
user> (do
(.start (Thread. lese-rohling))
(.start (Thread. brennen)))
lesen1 leer
brennen leer
lesen1 gebrannt
lesen2 gebrannt gebrannt
Hier wird die dereferenzierende Funktion wiederholt, da zwischenzeitlich ein schreibender
Zugriff auf die Ref erfolgte. Beim zweiten Dereferenzieren bemerkt die Transaktion den
schreibenden Zugriff und löst die Wiederholung aus.
Demgegenüber wird bei Verwendung von ensure die schreibende Funktion wiederholt, da
ihr Commit durch die noch laufende Transaktion behindert wird:
(def rohling (ref "leer"))
(defn ensure-rohling []
(dosync
(let [v (ensure rohling)]
(println "ensure1" v)
(Thread/sleep 2000)
(println "ensure2" @rohling v))))
user> (do
(.start (Thread. ensure-rohling))
(.start (Thread. brennen)))
ensure1 leer
brennen leer
brennen leer
brennen leer
ensure2 leer leer
user> @rohling
"gebrannt"
Die drei Wiederholungen von brennen sind durch die Sleep-Zeiten verständlich. Die erste
Wiederholung wartet bis 600 ms, die zweite bis 1200 ms und die dritte bis 1800 ms. Erst die
vierte Wiederholung der schreibenden Funktion ist erfolgreich, da dann die 2000 ms der
Transaktion, die ensure aufgerufen hat, abgelaufen sind.
Auch Refs unterstützen die Prüfung von Werten vor der Zuweisung mit Hilfe von
Validatoren, wie Abschnitt 3.4.5 beschreibt.
Der Referenztyp Agent bietet die Möglichkeit, Änderungen am verknüpften Wert asynchron
und serialisiert durchzuführen. Die Berechnung erfolgt in einem anderen Thread, und die
Änderungen integrieren sich in das Transaktionssystem der Refs.
Agents bieten sich somit für Anwendungsfälle an, in denen das Aktualisieren einer
Ressource nicht zeitkritisch ist; etwa wenn sich eine aufwendige Rechnung auf viele
Prozessoren verteilt und ein separater Thread gelegentlich den Fortschritt grafisch darstellen
soll. Gleichermaßen sind sie für Informationen geeignet, deren Änderungen eine
Queue-Semantik besitzen sollen.
Zum Erzeugen eines Agent dient die Funktion agent, die als Argument einen
Datentyp von Clojure erwartet:
Der Zugriff auf die enthaltene Information erfolgt durch Dereferenzieren mit
deref oder dessen Read-Syntax.
user> (def agts (agent ["James Bond"]))
#’user/agts
user> (type agts)
clojure.lang.Agent
user> @agts
"James Bond"
Um an einem Agent eine Änderung durchzuführen, kommt eine der Funktionen send
oder send-off zum Einsatz. Beide Funktionen nehmen den zu verändernden Agent, eine
Update-Funktion sowie optional weitere Argumente für die Update-Funktion entgegen.
In der Literatur wird diese Update-Funktion meist als „Aktion“ (engl. „Action“)
bezeichnet. Sie akzeptiert genau ein Argument – den aktuellen Zustand des Agent – und
liefert einen Wert zurück, der zum neuen Zustand wird. Aktueller AgentWährend der
Ausführung der Aktion ist die spezielle Var *agent* an den aktuellen Agent gebunden,
so dass aus einer Aktion weitere Aktionen an denselben Agent geschickt werden
können. Dabei ist die Eigenschaft von Vars, Änderungen nur lokal im Thread sichtbar
zu machen, notwendig: Im Thread des Agent hat *agent* immer den korrekten
Wert.
An der aufrufenden Stelle im Programm wird sofort weitergearbeitet, ohne das Resultat der
Aktion abzuwarten, die an einen separaten Thread aus einem dedizierten Thread-Pool
weitergereicht wird.
Die beiden Funktionen unterscheiden sich darin, dass send bei
nichtblockierenden Funktionen verwendet wird und einen Thread-Pool mit einer
konstanten Anzahl von Threads verwendet, während send-off für potenziell blockierende
Update-Funktionen, beispielsweise bei Dateizugriffen, geeignet ist und einen Thread-Pool
verwendet, dessen Anzahl von Threads wachsen kann. Somit ist send-off also die etwas
sicherere Variante. Idiomatischer Clojure-Code wird aber send bevorzugen, sofern das möglich
ist.
Wenn der Aufruf von send oder send-off aus einer Funktion erfolgt, die
im Rahmen einer Transaktion eine Ref zu manipulieren versucht, garantiert Clojure, dass die
Aktion des Agent – ungeachtet der eventuellen Wiederholungen der Funktion – nur einmal
aufgerufen wird. Diese Integration in die STM-Maschinerie ermöglicht beispielsweise
Reaktionen auf die Veränderung einer Ref.
Das folgende Beispiel demonstriert die Verwendung eines Vektors von Strings als
Wert im Agent. Dieser Vektor wird – mit Hilfe von send und conj – mit einer
wachsenden Anzahl von Strings gefüllt. Ein dedizierter Thread übernimmt das Senden an
den Agent, und ein zweiter Thread überwacht zehnmal die Anzahl der enthaltenen
Strings.
(def agts (agent ["James Bond"]))
(defn gehaltsliste-ueberwachen []
(dotimes [i 10]
(println i "#Agenten:" (count @agts))
(Thread/sleep 2)))
(defn agenten-einstellen []
(let [agenten ["Jerry Cotton"
"Phil Decker"
"John Steed"
"Emma Peel"
"Austin Powers"]]
(doseq [a agenten]
(send agts conj a)
(println "Gesendet" a "->" @agts)
(Thread/sleep 2))))
(defn geheimbund-aufbauen []
(.start (Thread. gehaltsliste-ueberwachen))
(.start (Thread. agenten-einstellen)))
user> (geheimbund-aufbauen)
0 #Agenten: 1
Gesendet Jerry Cotton -> [James Bond]
1 #Agenten: 2
Gesendet Phil Decker -> [James Bond Jerry Cotton]
2 #Agenten: 3
Gesendet John Steed -> [James Bond Jerry Cotton Phil Decker]
3 #Agenten: 4
Gesendet Emma Peel -> [James Bond Jerry Cotton Phil Decker
John Steed]
4 #Agenten: 5
Gesendet Austin Powers -> [James Bond Jerry Cotton Phil Decker
John Steed Emma Peel]
5 #Agenten: 6
6 #Agenten: 6
7 #Agenten: 6
8 #Agenten: 6
9 #Agenten: 6
10 #Agenten: 6
Das asynchrone Verhalten von Agents ist ein wesentliches Merkmal dieses
Referenztypen. Wenn dennoch Bedarf an einer Synchronisation mit einem Agent besteht, kann
auf await oder await-for zurückgegriffen werden. Beide nehmen eine Liste von Agents als
Argument entgegen und blockieren den aufrufenden Thread, bis alle genannten Agents die an
sie gesendeten Aktionen ausgeführt haben. Dabei blockiert await bis zum endgültigen
Abschluss der Arbeit der Agents; await-for implementiert einen Timeout, der in
Millisekunden übergeben wird.
(await agents*)
(await-for time-out-ms agents*)
Der Thread-Pool, in dem Agents ablaufen, enthält User-Threads. Diese
unterscheiden sich auf der JVM von den sogenannten Daemon-Threads vor allem dadurch,
dass sie das Beenden der JVM blockieren. Solange noch ein User-Thread arbeitet, kann die
JVM nicht herunterfahren. Es ist geplant, diese Eigenschaft in einer der kommenden Versionen
von Clojure zu ändern. Aktuell steht mit der Funktion shutdown-agents eine Möglichkeit zur
Verfügung, den Agents zu signalisieren, dass sie ihre Arbeit einstellen sollen. Nach Aufruf
dieser Funktion werden noch alle gesendeten Aktionen ausgeführt, jedoch keine neuen mehr
angenommen. Sobald alle Aktionen abgearbeitet sind, kann sich die JVM dann
beenden.
Eine interessantes Muster ist das Senden einer Aktion aus der Aktion selber. Auf diese
Weise kann ein System von sich gegenseitig oder selber immer wieder aufrufenden
Agents erstellt werden, eine Multithreading-Rekursion. Das nächste Beispiel zeigt
exemplarisch ein solches Verfahren. Die Funktion zeige-thread-action sendet sich
selber wieder an den Agent *t-1000*. In diesem Falle wird ein benannter Agent
verwendet, die Funktion könnte aber auch die Var *agent* verwenden. Das ausführliche
Beispiel in Abschnitt 3.8 setzt ebenfalls self-calling Agents ein und verwendet dabei
*agent*.
user> (def *t-1000* (agent {:count 0}))
#’user/*t-1000*
user> @*t-1000*
{:count 0}
(defn zeige-thread-action [state]
(println "In Thread" (.getName (Thread/currentThread)))
(if (< (:count state) 5)
(do (send *t-1000* zeige-thread-action)
(assoc state :count (inc (:count state))))
state))
user> (send *t-1000* zeige-thread-action)
In Thread pool-1-thread-1
#<Agent@4963f7a1: {:count 1}>
user> In Thread pool-1-thread-2
In Thread pool-1-thread-3
In Thread pool-1-thread-4
In Thread pool-1-thread-4
In Thread pool-1-thread-4
Die asynchrone Natur von Agents macht es notwendig, Fehlerszenarien besonders zu
behandeln. Konnten bei Atoms noch Exceptions aus einer Update-Funktion entstehen, die im
Code an der Stelle, die das Update ausgelöst hat, behandelt werden können, ist das bei Agents
nicht mehr der Fall. Der Grund dafür ist schlicht, dass ihre Updates zu einem späteren
Zeitpunkt in einem anderen Thread ausgeführt werden. Die auslösende Funktion aber kann,
ohne zu warten, weiterarbeiten.
Ein Agent gilt als fehlerhaft, wenn in der Update-Funktion eine
Exception auftaucht. Alternativ kann ein Update fehlschlagen, weil ein unerlaubter Wert in
den Agent gespeichert werden sollte. Dies überprüft eine Validator-Funktion, was in
Abschnitt 3.4.5 beschrieben wird.
Die Fehlerbehandlung von Agents hat sich in Clojure 1.2 grundlegend geändert.
Wir beschreiben hier nur noch das neue Verfahren.
Wie ein Agent auf einen Fehlerzustand reagiert, hängt davon ab, was sein
Fehlermodus (engl. error-mode) ist. Agents können einen von zwei verschiedenen Fehlermodi
besitzen: :fail oder :continue. Von diesen ist :fail der Default, der ohne nähere Spezifikation
verwendet wird. Mit der Funktion error-mode kann der Modus jederzeit ermittelt
werden.
Im Modus :fail verwirft der Agent das Update, behält also den alten Wert und akzeptiert
darüber hinaus keine weiteren Aktionen.
(def doppel-agent (agent "Villariba"))
(defn ueberlaufen [aktuell neu]
(if (and (= aktuell "Villariba")
(= neu "Villabajo"))
(throw (Exception. "Aufgedeckt!"))
neu))
user> (error-mode doppel-agent)
:fail
user> (send doppel-agent ueberlaufen "Villabajo")
#<Agent@a8198c FAILED: "Villariba">
user> @doppel-agent
"Villariba"
user> (send doppel-agent ueberlaufen "Villabajo")
java.lang.RuntimeException: Agent is failed, needs restart
Ausgabe von Agents
Die Ausgabe von Agents an der REPL erfolgt im Thread der REPL. Je nach Laufzeitverhalten kann die Ausgabe von Agents nach dem Senden einer Funktion bereits den neuen Wert oder noch den alten anzeigen. Auch der Status „FAILED“ ist nicht immer gleich sichtbar. Hier wird die asynchrone Natur der Agents sichtbar.
Soll der Agent weiterarbeiten, muss er durch einen Aufruf der Funktion
restart-agent zurückgesetzt werden. Diese Funktion erwartet als Argumente den Agent
sowie den neuen Statuswert, den der Agent annehmen soll. Auch dieser Wert würde
durch eine Validator-Funktion zuvor überprüft werden. Sollte beim Zurücksetzen ein
Fehler auftauchen, wird sich an dem aktuellen Zustand nichts ändern. Ein Aufruf von
restart-agent auf einem Agent ohne Fehler ist nicht korrekt und führt zu einer
Exception.
user> (restart-agent doppel-agent "Villariba")
"Villariba"
user> (send doppel-agent ueberlaufen "Portunesien")
#<Agent@7cb66a: "Portunesien">
user> @doppel-agent
"Portunesien"
user>
Etwas weniger streng verhalten sich Agents, deren Fehlermodus mit Hilfe von
set-error-mode! auf :continue gesetzt wurde. In diesem Falle verwirft der Agent einfach das
Update und verhält sich so, als wäre das Update nie begonnen worden.
Zusätzlich zum Fehlermodus kann einem Agent eine Funktion als
Rückruffunktion (engl. Callback) im Fehlerfalle übergeben werden. Clojure bezeichnet diese
Funktion englisch als Error-Handler. Sie wird im Fehlerfalle mit zwei Argumenten aufgerufen:
dem Agent und der aufgetretenen Exception. Auf diese Weise ließe sich etwa ein
solcher Fehler protokollieren, während das System jedoch weiterhin arbeiten kann.
Wenn ein Agent einen Error-Handler besitzt, ist der Fehlermodus ohne explizite
Angabe :continue, da davon auszugehen ist, dass sich der Anwender um den Fehler
kümmert.
Beide Eigenschaften, Fehlermodus und Error-Handler, können bei der Anlage eines Agent
auch als Keyword-Argumente übergeben werden.
Das folgende Beispiel stellt dar, wie eine Rückruffunktion aufgerufen wird und welche
Argumente sie bekommt. Dazu wird eine Funktion als Aktion an einen Agent geschickt, die
lediglich eine Exception wirft.
(defn handler-fktn [a e]
(println "Agent, State:" @a)
(println "Fehler: " e)
"Handler fertig")
(defn werfer [& args]
(println "Werfer, args" args)
(throw (Exception. "Meine Exception")))
(def a (agent "A"
:error-handler handler-fktn
:error-mode :continue)) ; auch default
user> (send a werfer)
#<Agent@7dd41116: "A">
Werfer, args (A)
Agent, State: A
Fehler: #<Exception java.lang.Exception: Meine Exception>
user> @a
"A"
Ein klassisches Beispiel für die Synchronisierung mehrerer Threads ist die Interaktion zwischen
Programmteilen, die Daten erzeugen, und anderen, die diese weiterverarbeiten. Für solche
Szenarien bieten sich Agents vor allem durch ihr serielles Verhalten an.
Eine denkbare Anwendung ist das Parsen von Logdateien: Ein Programmteil liest ein
zeilenbasiertes Format ein, ein anderer ermittelt die gewünschten Statistiken. Der Gewinn
durch Parallelisierung hängt hier stark von der verarbeitenden Funktion ab, kann auch durch
die I/O-Leistung limitiert sein.
user> (use ’[clojure.java.io :only (reader)])
nil
(def *ip-zaehler-agent* (agent {}))
(defn inc-map-zaehler [a-map a-key]
(let [cur-count (get a-map a-key 0)]
(assoc a-map a-key (inc cur-count))))
(defn tokenize-zeile [zeile]
;; vereinfacht: nur remote ip
{:remote-ip (subs zeile 0 (.indexOf zeile " "))})
(defn parse-apache-log [filename]
(with-open [rdr (reader filename)]
(doseq [l (line-seq rdr)]
(let [e (tokenize-zeile l)]
(send *ip-zaehler-agent*
inc-map-zaehler
(e :remote-ip))))))
user> (parse-apache-log "access.log")
nil
user> @*ip-zaehler-agent*
{"93.158.148.x" 1, "65.55.207.x" 2, "74.222.4.x" 2,
"65.55.106.x" 1, "92.76.249.x" 3, "202.78.240.x" 1}
Im Vergleich zu den üblichen Implementationen gibt es hier keine explizite blockierende
Queue oder andere Synchronisationsmechanismen, die Kommunikation zwischen dem synchron
im Hauptthread laufenden Produzenten und der asynchronen Verarbeitung geschieht einzig
durch die Funktion send.
Das Transaktionssystem der Refs und die atomare Behandlung von Änderungen
implementieren das „A“ und „I“ der ACID-Transaktionseigenschaften, „D“ kann bei
Transaktionen im Speicher, also ohne Persistenzschicht, nicht erfüllt werden. Die
Sicherstellung der Konsistenz, das „C“, erfüllen die Datentypen Atom, Ref und Agent, indem
sie bei der Anlage eine Funktion, die die Validierung vornimmt, akzeptieren. Ein einfaches
Beispiel ist die Prüfung des Typs, etwa einer ganzen Zahl.
user> (def cl-zahl (atom 0 :validator integer?))
#’user/cl-zahl
user> (reset! cl-zahl "Cl")
java.lang.IllegalStateException: Invalid reference state
user> (reset! cl-zahl 17)
17
Die Validierung wird nicht nur bei Updates, sondern auch beim ersten Wert
durchgeführt, wie das folgende Beispiel zeigt.
user> (def zahlstring (atom "Eins" :validator integer?))
java.lang.RuntimeException: java.lang.IllegalStateException:
Invalid reference state
Natürlich lassen sich hier auch beliebige andere Funktionen angeben, die alle ein Argument,
den zu testenden neuen Wert, akzeptieren müssen:
user> (def ordnungszahl (atom 1 :validator #(< 0 % 119)))
#’user/ordnungszahl
user> (defn traum-in-dubna []
"Ununonium!"
(reset! ordnungszahl 119))
#’user/traum-in-dubna
user> (traum-in-dubna)
java.lang.IllegalStateException: Invalid reference state
Validator-Funktionen liefern true zurück, wenn sie den neuen Wert
akzeptieren. Im Falle von false wird – wie gezeigt – eine IllegalStateException geworfen.
Gleiches gilt, wenn die Validator-Funktion selbst eine Exception wirft.
Wenn die Definition eines Referenztypen bereits erfolgt ist, kann auf die Validierungsfunktion
mit den Funktionen get-validator und set-validator! zugegriffen werden. Erstere liefert
die Funktion zurück, zweitere setzt sie erneut. Im Beispiel mit den Ordnungszahlen könnte ein
anerkannter wissenschaftlicher Durchbruch eine neue Validierungsfunktion notwendig
machen.
user> (get-validator ordnungszahl)
#<user$fn__1136 user$fn__1136@1970ae0>
user> (def frei (atom ["Akzeptiert" "alles"]))
#’user/frei
user> (get-validator frei)
nil
user> (set-validator! ordnungszahl #(< 0 % 120))
nil
user> (traum-in-dubna)
119
user> @ordnungszahl
119
Die Funktionen, die als Validatoren zum Einsatz kommen, müssen frei von
Nebenffekten sein. Insbesondere dürfen sie keine anderen Refs lesen. Somit eignen sich
Validatoren ausdrücklich nicht dazu, sicherzustellen, dass mehrere Refs gemeinsam eine
Bedingung erfüllen.
Alle vier Referenztypen unterstützen in Clojure 1.2 sogenannte Watcher. Es handelt sich
dabei um Funktionen, die bei Änderungen am Referenztypen aufgerufen werden. Watcher
werden mit der Funktion add-watch angelegt und mit remove-watch wieder entfernt. Die
Dokumentation dieser Funktionen kennzeichnet sie ausdrücklich als Alpha-Versionen, so dass
wir von einer tiefergehenden Beschreibung absehen. Ein ganz kurzes Beispiel zeigt die generelle
Funktionsweise.
(defn mein-watcher [k f old new]
(println "Watcher"
[k f old new]))
(def die-ref (ref "Anfang"))
user> (add-watch die-ref :schluessel mein-watcher)
#<Ref@860315: "Anfang">
user> (dosync
(ref-set die-ref "Ende"))
Watcher [:schluessel #<Ref@860315: Ende> Anfang Ende]
"Ende"
Watcher eignen sich beispielsweise für die Protokollierung von Änderungen und – mit
Abstrichen – auch für das Speichern einer Datenstruktur auf einem nichtflüchtigen Medium.
Das letztgenannte Verfahren ist aber ausdrücklich nicht transaktionssicher.
Clojures Daten sind unveränderlich bis auf die Referenztypen und aus Java importierte
Objekte. Die Unveränderlichkeit der Daten bringt im Zusammenspiel mit anderen
Technologien Vorteile. Wenn wirklich Daten verändert werden müssen, um den Verlauf
von Zeit zu modellieren, bietet Clojure hierfür mit den Referenztypen verschiedene
Vorgehensweisen.
Eine Hilfestellung für die Entscheidung, welcher Referenztyp für das vorliegende Problem
geeignet ist, gibt die folgende Gegenüberstellung der verschiedenen Typen.
| Tabelle 3.1: | Referenztypen |
|
|
|
|
| Typ | Kontext | Koordination | Ausführung |
|
|
|
|
| Var | lokal | eine Identität | synchron |
| Atom | übergreifend | eine Identität | synchron |
| Ref | übergreifend | mehrere Identitäten | synchron |
| Agent | übergreifend | eine Identität | asynchron |
|
|
|
|
| |
-
Atom
- Atoms koordinieren Thread-übergreifend Lesen und Schreiben eines einzelnen
Werts. Änderungen sind in anderen Threads sichtbar. Zum Zugriff auf den Wert
wird das Atom dereferenziert.
-
Ref
- Refs verhalten sich weitgehend so wie Atoms. Allerdings erlaubt Clojure durch
Einsatz von STM die konsistente Manipulation mehrerer Refs.
-
Agent
- Agents arbeiten asynchron und seriell. Dadurch wird die Fehlerbehandlung
aufwendiger. Auch bei ihnen erfolgt der Zugriff durch Dereferenzieren.
-
Var
- Vars unterscheiden sich von den drei anderen Referenztypen wesentlich. Der Zugriff
auf ihren Inhalt erfolgt implizit, es ist kein Dereferenzieren notwendig. Änderungen
gelten nur lokal pro Thread, es findet keine Kommunikation mit anderen
Threads statt. Ihr Einsatzzweck ist primär ein Container für benannte Objekte
wie Funktionen, Makros oder Werte. Durch die Eigenschaft der dynamischen
Variablenbindung erlauben sie Einflussnahme auf die Arbeitsweise einer Funktion
neben der Parameterübergabe.
Die Referenztypen spielen die zentrale Rolle bei der Koordination von Zugriffen auf
geteilte Informationen. Damit es überhaupt etwas zu koordinieren gibt, muss die
Anwendung separate Threads erzeugen und die zu verrichtende Arbeit auf diese
verteilen. Dieser Abschnitt befasst sich mit der Erzeugung von Threads und wie
sich auf den grundlegenden Mechanismen andere Konzepte entwickeln lassen. Die
Methoden zur Erzeugung lassen sich grob nach ihrer Herkunft und ihrer Verwendung
gruppieren.
- Direkter Zugriff auf das Portfolio von Java,
- Funktionen aus dem Angebot von Clojure,
- Parallelisierung.
Die beiden erstgenannten zielen dabei eher auf Multithreading zur gleichzeitigen
Bearbeitung verschiedener Jobs, während sich die letzte mit der Verteilung einer Aufgabe auf
mehrere Prozessoren beschäftigt.
Die einfachste Art, einen Thread zu erzeugen, die auch bereits mehrfach Verwendung gefunden
hat, ist die Erzeugung einer Instanz von Thread. Typische Java-Anwendungen leiten entweder
eine eigene Klasse von Thread ab oder aber implementieren das Interface Runnable und dort
die Methode run. Clojures Funktionen gehen den zweiten Weg und können somit an einen
Thread übergeben werden. Als Beispiel dient eine Funktion, die aus dem aktuellen Thread
einige Parameter liest und ausgibt.
(defn th-info []
(let [t (Thread/currentThread)]
{:Name (.getName t)
:ID (.getId t)
:Prio (.getPriority t)
}))
(defn print-th-info []
(println
(interpose "\n" (th-info))))
Im Thread der REPL angewendet, zeigt sie dessen Namen, ID und Priorität:
user> (print-th-info)
([:Name main]
[:ID 1]
[:Prio 5])
nil
Andere Threads bekommen einen automatischen Namen und eine neue ID:
user> (.start (Thread. print-th-info))
([:Name Thread-3]
[:ID 15]
[:Prio 5])
nil
user> (.start (Thread. print-th-info))
([:Name Thread-4]
[:ID 16]
[:Prio 5])
nil
Auf Wunsch kann dem Thread auch ein dedizierter Name gegeben werden. Das folgende
Beispiel verwendet das Makro doto, um Wiederholungen der Instanz-Variable zu vermeiden.
Dies wird in Abschnitt 4.1.1 beschrieben.
user> (doto (Thread. print-th-info)
(.setName "Ich, Thread")
(.start))
#<Thread Thread[Ich, Thread,5,main]>
([:Name Ich, Thread]
[:ID 17]
[:Prio 5])
user>
Diese Methode, einen Thread zu erzeugen, ist jedoch wenig flexibel.
Java-Programmierer kennen Executor respektive ExecutorService als flexibleren Mechanismus,
der auch die Implementation von Thread-Pools erlaubt, also wiederverwendbare Threads, die
ein Runnable laufen lassen, ohne dass pro Runnable ein neuer Thread erzeugt werden
müsste.
Da Clojure den direkten Zugriff auf Java-Klassen und -Methoden erlaubt, steht es
Clojure-Entwicklern frei, sich für eine dieser Methoden zu entscheiden. Dann gilt es allerdings,
alle Nebeneffekte zu beachten, die bei Verwendung solcher Thread-Pools und Services
auftauchen können. Die JDK-Dokumentation enthält Hinweise darauf, welche Aktivitäten in
welcher Reihenfolge durchgeführt werden. Somit erscheint die direkte Verwendung solcher
Pools wenig typisch für Clojure-Programme.
Ein Blick hinter die Kulissen zeigt aber, dass die in Abschnitt 3.4.4 beschriebenen
Agents gerade diese Technologie verwenden. Zudem integrieren sie sich mit dem
Transaktionssystem der Refs. Clojure macht somit die korrekte Verwendung von
ExecutorService einfacher, vor allem wenn die Threads auch Statusinformationen in Refs oder
Agents ändern sollen. Wer sich nur mit Clojure befassen möchte, braucht sich um die Details
der grundlegenden Java-Klassen nicht zu kümmern und kann sich auf das Modell der Agents
verlassen.
Selbstverständlich kann aber auch das Java-Konstrukt verwendet werden,
beispielsweise, um einen eigenen Thread-Pool zu verwalten.
user> (import ’(java.util.concurrent Executors))
java.util.concurrent.Executors
(def mein-tpool (Executors/newFixedThreadPool 3))
user> (.getPoolSize mein-tpool)
0
user> (.getMaximumPoolSize mein-tpool)
3
user> (.execute mein-tpool print-th-info)
nil
([:Name pool-3-thread-1]
[:ID 18]
[:Prio 5])
user> (.getPoolSize mein-tpool)
1
user> (def dummies (repeat 5 print-th-info))
#’user/dummies
user> (.invokeAll mein-tpool dummies)
([:Name pool-3-thread-1]
[:ID 18]
[:Prio 5])
([:Name pool-3-thread-1]
[:ID 18]
[:Prio 5])
([:Name pool-3-thread-1]
[:ID 18]
[:Prio 5])
([:Name pool-3-thread-2]
[:ID 19]
[:Prio 5])
([:Name pool-3-thread-3]
[:ID 20]
[:Prio 5])
#<ArrayList
[java.util.concurrent.FutureTask@49d8fe,
java.util.concurrent.FutureTask@452997,
java.util.concurrent.FutureTask@ad9c8b,
java.util.concurrent.FutureTask@9e57,
java.util.concurrent.FutureTask@9b69f6]>
user> (.getPoolSize mein-tpool)
3
In diesem Beispiel wird explizit ein eigener Thread-Pool mit drei enthaltenen Threads
angelegt. Zu Beginn ist dieser, wie der Aufruf von getPoolSize zeigt, noch leer, es ist aber
Raum für bis zu drei Threads, was getMaximumPoolSize anzeigt. Im Anschluss wird
auf dem aktuellen, dem REPL-Thread, die Funktion print-th-info einmal mit
Hilfe von execute ausgeführt. Danach enthält der Pool einen Thread. Um dem Pool
etwas Arbeit zu geben, erzeugt repeat eine Sequence, die fünfmal die Funktion
print-th-info enthält, und übergibt diese durch den Aufruf von invokeAll an den Pool. Die
folgenden Zeilen enthalten die Ausgabe, an der erkenntlich wird, wie weitere Threads
für die Arbeit erzeugt werden. Abschließend hat der Pool seine maximale Größe
erreicht.
Vollkommen ohne explizites Thread-Handling kommt die Methode future aus. Mit ihrer
Verwendung drückt der Programmierer aus, dass er einen Programmteil irgendwann in einem
anderen Thread ausgeführt wissen möchte. Das Resultat kann durch DereferenzierenDereferenzieren
der Var zu einem beliebigen späteren Zeitpunkt erfolgen. Sollte das Ergebnis bis dahin noch
nicht feststehen, wird der dereferenzierende Ausdruck blockieren, bis das Ergebnis
vorliegt.
(defn langsamer-wert []
(Thread/sleep 5000)
(System/currentTimeMillis))
(defn test-fut []
(println "Start" (System/currentTimeMillis))
(let [spaeter (future (langsamer-wert))]
(println "Davor" (System/currentTimeMillis))
(println "Deref" (deref spaeter))
(println "Danach" (System/currentTimeMillis))))
user> (test-fut)
Start 1268083317644
Davor 1268083317645
Deref 1268083322645
Danach 1268083322646
nil
Für diese Funktion verwendet Clojure einen anonymen Typen, der
sowohl das Clojure-eigene Interface IDeref für dereferenzierbare Objekte als auch
java.util.concurrent.Future implementiert. Die Hintergründe dieses Verfahrens beschreibt
Abschnitt 5.3.3. Die Berechnung erfolgt in einem Thread aus dem Pool der Agents. Die
asynchrone Natur von Futures zeigt ihre Verwandtschaft mit Agents. Allerdings verfügen sie
über keinerlei Warteschlangensemantik, mit der sie konkurrierende Zugriffe auf einen Wert
koordinieren.
Futures kennen zwei Prädikate, die testen, ob es sich um ein Future handelt und ob es
schon berechnet wurde: future? und future-done?. Im folgenden Beispiel wurde die
letztgenannte Methode in schneller Folge dreimal aufgerufen, bis im Hintergrund der
Future-Thread die Arbeit erledigt hatte.
user> (def kommt-gleich (future (langsamer-wert)))
#’user/kommt-gleich
user> (future-done? kommt-gleich)
false
user> (future-done? kommt-gleich)
false
user> (future-done? kommt-gleich)
true
user> (future? kommt-gleich)
true
Das Java-Interface Future ermöglicht es zudem, ein entsprechendes Objekt vorzeitig zu
beenden. Die Clojure-Funktion dafür ist future-cancel, und mit future-cancelled?
kann der Zustand diesbezüglich abgefragt werden. Wurde ein Future abgebrochen,
wird beim Dereferenzieren eine Exception geworfen. Auch Futures operieren am
besten mit reinen Funktionen, ohne Nebeneffekte, denn speziell im Fehlerfalle und
beim Abbruch, ist der Programmierer gehalten, eventuelle Nebeneffekte selbst zu
behandeln.
In der Einleitung zu diesem Kapitel wurden die zwei verschiedenen Arten der Concurrency
genannt: parallele Verarbeitung unabhängiger Teile eines Jobs und parallele Bearbeitung
verschiedener Jobs. Die bisher vorgestellten Methoden zur Erzeugung von Threads fokussieren
auf die letztgenannte Variante.
Für die Parallelverarbeitung einer Aufgabe empfiehlt sich vor allem der Einsatz von
pmap. Die Beispiele in Abschnitt 3.8 und 4.3 verwenden beide pmap, um eine hinreichend
komplexe Berechnung einzelner Werte einer Sequence auf Threads zu verteilen.
Der Aufruf gleicht dem von map, es werden lediglich im Hintergrund mit future
entsprechende Future-Objekte erzeugt, deren Berechnung in separaten Threads erfolgt. Wie
auch map liefert pmap eine Lazy Sequence der Werte zurück, allerdings legen die
Berechnungsfunktionen in den Beispielen ihre Werte als Nebeneffekt in einem Referenztypen
ab.
Mit Hilfe von pmap ist auch die Funktion pcalls implementiert, die eine Reihe von
Funktionen annimmt, diese in separaten Threads ausführt und eine Lazy Sequence der
Resultate zurückgibt.
user> (pcalls
#(Math/pow 22 10)
#(inc 99)
#(apply + (take 100 (iterate inc 1))))
(2.6559922791424E13 100 5050)
Dieses wenig hintergründige Beispiel verwendet Ad-hoc-Funktionen, um den Aufruf und das
Resultat von pcalls zu demonstrieren. In realen Projekten wird man eher die zu lösende
Aufgabe in separate Teilaufgaben zerlegen, deren parallel berechnete Ergebnisse abschließend
wieder zusammengefügt werden. Dann hilft pcalls bei der parallelen Verarbeitung eines Jobs,
wobei der Programmierer – im Gegensatz zum einfachen pmap – explizit die Aufteilung
vornimmt.
Das obige Beispiel wäre genau genommen eher ein Fall für pvalues, denn pvalues
unterscheidet sich von pcalls dadurch, dass es anstelle von Funktionen Ausdrücke annimmt
und parallelisiert.
user> (pvalues
(Math/pow 22 10)
(inc 99)
(apply + (take 100 (iterate inc 1))))
(2.6559922791424E13 100 5050)
Clojures Datentypen sind – wie in Abschnitt 3.2.1 beschrieben – im Allgemeinen
unveränderlich. Operationen wie zum Beispiel das Hinzufügen eines Elements zu einem Vektor
erzeugen eine neue Vektorinstanz, die viele ihrer internen Datenstrukturen mit dem
ursprünglichen Vektor teilt.
Verzicht auf Unveränderlichkeit
In einigen Fällen kann dieses Prinzip der Unveränderlichkeit
lästig oder zumindest überflüssig sein: Wenn in einer Funktion eine Datenstruktur in einem
oder mehreren Initialisierungsschritten mit Werten befüllt wird und sichergestellt werden
kann, dass der Code threadsicher ist, kann auf das Sicherheitsnetz der persistenten Datentypen
verzichtet werden.
Eine Möglichkeit wäre die Verwendung von Java-Datentypen (Array, ArrayList,
HashMap …), wodurch der Code jedoch sehr Clojure-untypisch würde, da anstelle
der Clojure-Funktionen zur Datenmanipulation auch die jeweilige Java-API zur
Anwendung käme. Theoretisch könnte diese Datenstruktur nach dem Befüllen in
einen Clojure-Datentyp gewandelt werden, was allerdings Laufzeitkosten von (n)
verursachen würde und somit bei einer großen Anzahl von Elementen nicht ratenswert
erscheint.
Clojure enthält für genau solche Anwendungsfälle transiente Datenstrukturen.
Diese sind in einem definierten Programmabschnitt veränderlich und werden nach erfolgter
Manipulation ausdrücklich zu einer persistenten Datenstruktur mit den gewohnten
Eigenschaften.
Ein einfaches Beispiel generiert einen Vektor mit den natürlichen Zahlen. Dazu erzeugt
die folgende Funktion zunächst mit Hilfe von transient eine transiente Variante von einem
Vektor. Auf dieser kann mit der speziell für Transienten vorgesehenen Funktion conj! operiert
werden. Nach Ablauf der Rekursion gibt persistent! einen persistenten Vektor
zurück.
(defn fill-vec [k]
(loop [i 0 v (transient [])]
(if (< i k)
(recur (inc i) (conj! v i))
(persistent! v))))
(def fv (fill-vec 100))
user> (type fv)
clojure.lang.PersistentVector
user> (take 10 fv)
(0 1 2 3 4 5 6 7 8 9)
Ganz ähnlich sieht die Funktionsweise bei Maps aus, bei denen assoc! die Manipulation
der transienten Map übernimmt.
(defn fill-map [k]
(loop [i 0 m (transient {})]
(if (< i k)
(recur (inc i) (assoc! m i (* i i)))
(persistent! m))))
(def tm (fill-map 100))
user> (type tm)
clojure.lang.PersistentHashMap
user> (take 5 tm)
([0 0] [32 1024] [64 4096] [96 9216] [1 1])
Der Startwert einer Transienten kann eine beliebige Datenstruktur sein, auch eine bereits
gefüllte. Dann werden die ursprünglichen Inhalte weiterverwendet und manipuliert, wobei das
Original selbstverständlich unverändert bleibt.
user> (def mm {:a 1 :b 2})
#’user/mm
user> (-> mm
transient
(assoc! :a 99)
persistent!)
{:a 99, :b 2}
user> mm
{:a 1, :b 2}
Die Implementation von Clojure garantiert, dass die Umwandlung einer transienten in eine
persistente Datenstruktur in konstanter Laufzeit erfolgt, also nicht mit der Elementanzahl
steigt.
Ein Vergleich mit einer Implementation, die keine Transienten verwendet, zeigt die
Steigerung der Geschwindigkeit:
(defn fill-vec-persist [k]
(loop [i 0 v []]
(if (< i k)
(recur (inc i) (conj v i))
v)))
user> (time (dorun (fill-vec-persist 1000000)))
"Elapsed time: 1020.711 msecs"
user> (time
(dorun
(fill-vec 1000000)))
"Elapsed time: 562.366 msecs"
nil
Allerdings ist der Overhead der Transienten bei wenigen Manipulationen an der
Datenstruktur auch zu erkennen:
user> (time
(dorun
(fill-vec-persist 100)))
"Elapsed time: 0.050 msecs"
nil
user> (time
(dorun
(fill-vec 100)))
"Elapsed time: 0.085 msecs"
nil
Wie bei vielen Möglichkeiten der Optimierung sind auch Transienten mit Vorsicht zu
genießen. Zudem ist es häufig sinnvoll, den Funktionen, die es bereits gibt, zu vertrauen: Das
gleiche Ergebnis lässt sich auch mit Lazy Sequences erzielen. Dieses Vorgehen ist noch etwas
schneller als die Variante mit Transienten:
user> (time
(dorun
(take 1000000
(iterate inc 0))))
"Elapsed time: 480.824 msecs"
nil
Transienten lassen sich nur von einem Thread ändern. Bei Zugriff von einem
anderen Thread kommt es zu einer Exception vom Typ IllegalAccessError. Damit entfallen
sowohl die Möglichkeit als auch die Notwendigkeit einer Synchronisation über Thread-Grenzen
hinweg. Daraus folgt auch, dass die Manipulation von Transienten ohne Locks erfolgt.
Lesender Zugriff auf Transienten ist durch die gleichen Funktionen gegeben, die auch den
lesenden Zugriff auf den persistenten Varianten gewähren.
Die in Abschnitt 3.2.2 beschriebene Implementation der
Datenstrukturen sorgt dafür, dass die Handhabung der Datenstrukturen schnell ist. Eine
gezielte und vorsichtige Optimierung eines erwiesenen Nadelöhrs kann dennoch die
Performance eines Programms erheblich steigern. Die Verwendung von transienten Datentypen
kann eine solche Optimierung sein. Allerdings sollte sie wie – alle Optimierungen – nur an
relevanten Stellen zum Einsatz kommen, und der Geschwindigkeitsunterschied sollte durch
Messungen verifiziert werden.
In diesem Abschnitt geben wir in Kürze einige Hintergrundinformationen über Clojures
Implementation von Software Transactional Memory wieder. Die grundlegenden Funktionen
sind im Java-Code von Clojures Implementation in der Datei LockingTransaction.java zu
finden, aber die Funktionen, die für STM notwendig sind, reichen bis in die Implementationen
von etwa Refs oder Agents hinein. Daran ist ersichtlich, dass STM nicht – oder zumindest
nicht leicht – als eine modulare Funktion, als eine Bibliothek, betrachtet werden kann. Sie ist
in Clojure tief integriert.
Eigentlich sollten die Hintergründe für den Anwender von Clojure nicht relevant sein. Wie an
anderer Stelle, etwa in Abschnitt 7.1, beschrieben wird, ist dieser Zustand noch nicht erreicht.
Die derzeit beste Quelle, neben dem Quelltext, ist der Artikel „Software Transactional
Memory“ von Mark Volkmann [73].
Nur eine Transaktion pro Thread
Transaktionen sind lokal pro Thread. Jeder Thread kann
gleichzeitig nur an genau einer Transaktion teilnehmen. Läuft ein Thread in eine weitere
Transaktion, so fusioniert diese mit der ersten. Die erste Transaktion übernimmt dabei die
Steuerung. Darauf ist zu achten, wenn Transaktionen auf verschiedenen Ebenen des Stacks
ausgeführt werden.
Für die Implementation bedient sich Clojure der in java.util.concurrent
angebotenen Klassen. Wichtig ist die Verwendung eines CountDownLatch-Objekts,
das bei Beginn einer Transaktion mit einem Startwert von eins beginnt und am
Ende der Transaktion herunterzählt. Bei einem Timeout, wenn die Transaktion
darauf wartet, dass eine andere den CountDownLatch durch erfolgreiches Beenden
dekrementiert, kann dieser Wert ebenfalls heruntergezählt werden, was zu einer Wiederholung
führt.
Grenze für Wiederholungen
Es gibt eine Begrenzung, wie oft eine Transaktion wiederholt werden
darf. Diese ist in Clojure 1.2 auf 10 000 Versuche gesetzt. Bei Überschreiten dieses Limits wird
eine Transaktion eine Exception werfen. Genau genommen müssten also alle Transaktionen
durch entsprechendes Fangen der Exception abgesichert werden. Hier liegt jedoch ein ähnlicher
Fall vor wie bei der Beschränkung, wie viele Objekte in einer persistenten Datenstruktur
aufgenommen werden können. Faktisch wird dieser Wert nicht erreicht werden. Absolut
wasserdicht ist es aber nicht.
In einer Transaktion, in der eine Ref mit Hilfe von commute manipuliert
wird, darf diese nicht danach mit Hilfe von alter oder ref-set! verändert werden.
Hintergrund dessen ist, dass commute in der Transaktion eine gesonderte Behandlung
erfährt.
(def r1 (ref 1))
(defn alt-und-alt []
(dosync
(alter r1 inc)
(alter r1 inc)))
user> (alt-und-alt)
3
user> @r1
3
(def r2 (ref 2))
(defn comm-und-alt []
(dosync
(commute r2 inc)
(alter r2 inc)))
user> (comm-und-alt)
java.lang.IllegalStateException: Can’t set after commute
Der Aufruf von commute stellt sicher, dass es keine Deadlocks geben kann, indem
vor dem Commit der Werte auf alle Refs in der Reihenfolge ihrer Definition ein
Lock geholt wird. Somit gehen alle Transaktionen in der gleichen Reihenfolge vor,
und es kann nicht geschehen, dass eine Transaktion auf eine andere wartet und
umgekehrt.
Die Entwicklung hochgradig paralleler Anwendungen führt zu neuen Problemen. Nur die
Erfahrung, die jeder Entwickler selbst macht, wird helfen können, dieser Probleme
Herr zu werden. Sowohl im Diskussionsforum von Clojure als auch im IRC-Channel
werden gelegentlich solche Fälle besprochen. So fiel einem Anwender auf, dass seine
Applikation, die viele Zufallszahlen erzeugt, nicht gut skalierte. Der Grund dafür
ist, dass die Funktion rand-intrand-int einen Flaschenhals darstellt. Es wird ein
einziger Zufallszahlengenerator von allen Threads verwendet. Dies lässt sich durch
einen dedizierten Generator, der zum Thread gehört, umgehen. Nur muss man da
erst mal drauf kommen. Garbage CollectorÄhnlich verhält es sich mit Javas Garbage
Collector. In der Standardeinstellung arbeitet dieser nicht parallel und ist somit
ebenfalls ein Nadelöhr, das die Skalierung über Prozessoren negativ beeinflussen
kann [65].
Auch Meikel Brandmeyers Zusammenfassung einer Diskussion [9], die das
Problem des transparenten Speicherns von Ergebnissen einer Berechnung („Memoize“)
betrachtet, zeigt, dass es bei dieser Art zu programmieren ungewohnte, neue Fallstricke
gibt.
Das als Write Skew bekannte Problem gilt auch für Clojure. Es tritt auf, wenn
Validatoren verwendet werden, um die Konsistenz der Daten sicherzustellen. Jeder Validator
agiert nur für eine einzelne Ref, es findet keine Prüfung auf ein Ensemble von Werten statt.
Wenn beispielsweise die Summe von zwei Refs einen bestimmten Wert nicht übersteigen darf,
so prüft ein Validator das immer mit den dereferenzierten Werten, die er in der Transaktion
vorfindet; er trifft seine Entscheidung aber nur für eine der beiden Refs. Zeitgleich kann in
einer anderen Transaktion der Wert der anderen Ref geprüft werden. Beide kommen dann
unter Umständen zu dem Schluss, dass die Summe nicht überschritten wird. Wenn darauf
beide Transaktionen commiten, kann die Summe der beiden Refs größer sein als das
gesetzte Limit. Zur Vermeidung dieses Effekts kann die Funktion ensure eingesetzt
werden, die die Manipulation einer dereferenzierten Ref durch eine andere Transaktion
verhindert.
Verschiedene Transaktionen bekommen jeweils ihren eigenen Snapshot
der Daten in den beteiligten Refs. Dazu halten Refs ihre eigene Historie vor, die im
Konstruktor mit den Schlüsselwörtern :min-history und :max-history angegeben werden
können. Ohne diese Angabe wird keine minimale Historie verwendet, und die maximale
Anzahl von internen historischen Kopien beträgt zehn. Diese Historie wird immer dann
erweitert, wenn eine Transaktion versucht hat, den Wert einer Ref zu lesen, dieser sich in
der Zwischenzeit jedoch verändert hat. Zum Problem kann das führen, wenn die
Transaktionen, die versuchen, eine Ref zu verändern, signifikant unterschiedliche
Laufzeiten haben. Im schlimmsten Falle kommt die langsame Transaktion niemals an
ihr Ende und wird so oft wiederholt, bis eine interne Grenze für die Anzahl der
Wiederholungen (aktuell 10 000) erreicht ist. In dem Falle schlägt die Transaktion mit einer
Exception fehl. In der Praxis sollte dies keine Rolle spielen. Es ist jedoch etwas, das ein
Programmierer beim Design seiner Transaktionen im Hinterkopf haben sollte. Generell sollten
Transaktionen möglichst wenig beinhalten. Bei einer parallelen Berechnung etwa,
sollte die aufwendige Numerik außerhalb der Transaktion erfolgen, lediglich die
Bereitstellung der Ergebnisse in einer zentralen Datenstruktur erfordert Refs und
STM.
Ein kurzer Demo-Code von Chris Houser [36], der einer Diskussion am 28. Juni 2010
entsprungen ist, zeigt anhand zweier Threads, von denen einer eine langsame Transaktion mit
einem Reader ausführt und der andere schnell die Werte erhöht, zu welchen Fällen es hier
kommen kann:
; STM history stress-test
(defn stress [hmin hmax]
(let [r (ref 0 :min-history hmin :max-history hmax)
slow-tries (atom 0)]
(future ;; langsame Transaktion
(dosync
(swap! slow-tries inc)
(Thread/sleep 200)
@r)
(println "a is:" @r "history:" (.getHistoryCount r)
"after:" @slow-tries "tries"))
(dotimes [i 500]
(Thread/sleep 10)
(dosync (alter r inc))) ;; schnelle....
:done))
;; Default Werte fuer Refs
user> (stress 0 10)
:done
a is: 500 history: 10 after: 26 tries
;; Dieses Ergebnis weist darauf hin, dass die langsame
;; Transaktion nicht erfolgreich durchgeführt werden konnte,
;; bevor die dotimes-Schleife komplett durchlaufen wurde
;; (und :done zurückgab).
user> (stress 0 30)
a is: 414 history: 20 after: 21 tries
:done
;; Hier wurde die langsame Transaktion erfolgreich beendet,
;; nachdem die Historie auf 20 angewachsen war.
;; Erfolg! Allerdings wurden 21 Versuche benötigt, um die
;; Historie von 0 wachsen zu lassen. Wir können helfen,
;; indem wir gleich mit größerer minimaler Historie starten:
user> (stress 15 30)
a is: 118 history: 20 after: 6 tries
:done
;; Dieses Mal nur 6 Versuche, ausreichend, um die Historie
;; von 15 auf 20 anwachsen zu lassen.
Clojure vereinfacht die Handhabung von Multithreaded-Programmen, sie enthebt den
Entwickler jedoch nicht von seiner Verantwortung, die Mechanismen seines Programms zu
durchschauen.
Ein Beispiel, an dem sich die grundlegende Veränderung eines Programms durch die
Einführung von Concurrency anschaulich studieren lässt, ist die Implementation eines
einfachen genetischen Algorithmus. Die klassische Vorgehensweise beschreibt der folgende
Pseudocode:
Initialisiere eine zufaellige Population
Wiederhole:
Erzeuge leere Zwischen-Population
Wiederhole:
Ziehe fitnessbasierte Eltern
Erzeuge Nachkommen (Rekombination, Mutation)
Schreibe Nachkommen in die Zwischen-Population
Wenn die Zwischen-Population voll ist:
Beende Fuellen der Zwischen-Population
Ersetze alte Population durch Zwischen-Population
Bewerte Nachkommen:
Fuer jedes Individuum:
Rufe Fitness-Funktion auf
Entscheide Erreichen des Zielkriteriums
Dabei werden Populationen sukzessive in Form von Generationen erzeugt, und pro
Generation gibt es ein oder mehrere beste Individuen in der Population. Ein offensichlicher
Einstiegspunkt für parallele Verarbeitung ist die Bewertung der Nachkommen. Diese ist in der
Regel vom Rest der Population vollkommen unabhängig und kann somit leicht über mehrere
Prozessoren verteilt werden.
Die Implementation der Population in C wird vermutlich einen Speicherbereich
bereithalten, in den die jeweiligen Programmteile ihr Ergebnis konfliktfrei schreiben
können. In dem Falle stellt sich die Frage nach einem konsequenterem Ansatz nicht. In
anderen Sprachen würde vielleicht wie hier eine Hash-Map verwendet werden, bei der
der Zugriff vermutlich koordiniert werden muss. Perl und Python bieten in ihren
Thread-Erweiterungen die klassischen Hilfsmittel wie Locks und Semaphoren. Beide
verweisen aber in ihrer Dokumentation darauf, dass es schwierig ist, diese Hilfmittel
korrekt einzusetzen, und raten zur Verwendung von Queues für die Übergabe von
Daten zwischen Threads. Wenn zudem in zusätzlichen Datenstrukturen statistische
Informationen oder auch Kopien ausgewählter Individuen vorgehalten werden sollen, wenn
komplizierte Algorithmen mit Inselpopulationen implementiert werden sollen, die
vielleicht die Migration eines Individuums von einer Population in eine andere vorsehen,
drängt das Problem der Koordination der verschiedenen Datenstrukturen in den
Vordergrund.
Clojure vereinfacht diese Koordination durch seine Referenztypen, und
somit ist es möglich, einen alternativen Ablauf, der nebenbei eine viel stärkere Ähnlichkeit
zum realen Vorbild hat, zu realisieren:
Initialisiere eine zufaellige Population
Erzeuge n Threads mit:
Ziehe fitnessbasierte Eltern
Erzeuge Nachkomme (Rekombination, Mutation)
Rufe Fitness-Funktion auf Nachkomme auf
Schreibe Nachkomme und Fitness in die Population
Rufe Funktion wieder auf
Erzeuge m Threads mit:
Wenn Groesse der Population ueber Schwellwert
Entferne umgekehrt fitnessbasiert
Rufe Funktion wieder auf
Erzeuge einen Thread mit:
Wenn Zielkriterium erreicht:
Sende Signal an alle Threads zum Beenden
In diesem Verfahren werden die Threads zum Erzeugen und Vernichten
von Individuen aufeinander abgestimmt, so dass die Population nicht permanent
wächst, aber darüber hinaus ist kaum Synchronisationsaufwand zu leisten. Einfügen
in die und Entfernen aus der Population erfolgen asynchron und durch geeignete
Mechanismen koordiniert, so dass keine Konflikte erfolgen. Im Folgenden entwickeln wir ein
größeres Beispiel. Es implementiert den soeben beschriebenen Algorithmus und
verwendet ein Atom als Population. Die genannten, weitergehenden Anwendungen
würden durch den Einsatz von Refs und damit der STM-Maschinerie ermöglicht
werden.
In diesem Beispiel spielt die Population die zentrale Rolle, denn alle
Threads lesen und schreiben auf dieser Datenstruktur. In diesem Falle ist ein Atom die beste
Wahl. Es handelt sich um eine Datenstruktur, deren Inhalt für alle Threads relevant ist, womit
eine Var ausscheidet. Eine Ref wird nicht benötigt, da nur eine Datenstruktur verwendet wird
und somit keine transaktionale Koordination notwendig ist. Bei dem genannten Beispiel einer
Migration von Individuen aus einer Population in eine andere wäre eine Ref die geeignete
Wahl. Zu guter Letzt entscheiden wir uns gegen Agents, da der Zugriff auf die Individuen
synchron erfolgen soll. Die Änderungen sollen sofort geschrieben werden, damit beim
nächsten Griff in die Population schon die neuen Individuen ausgewählt werden
können. Agents spielen aber bei der Steuerung des Gesamtsystems eine wichtige
Rolle.
(ns de.clojure-buch.genalg)
(def population (atom {}))
Genetische Algorithmen werden oft eingesetzt, um in einer komplizierten
Ziel-Landschaft das Optimum zu finden. Logistikplanung oder auch der Entwurf von
Stundenplänen sind klassische Beispiele. Dazu wird eine Repräsentation der Lösung
verwendet, dich sich als Kette von Werten, oftmals auch binär, darstellen lässt. In diesem
Beispiel vereinfachen wir das Ziel dahingehend, dass die Repräsentation einer Lösung mit der
Lösung übereinstimmt: Der Algorithmus soll auf einen Ziel-String, „Thursday Next“,
führen.
(def das-ziel "Thursday Next")
Die Fitness-Funktion fitness-bewerten hat dazu zwei Teile:
- die Bewertung der Längendifferenz mit zweifacher Wertung
- und die Anzahl der unterschiedlichen Zeichen.
(defn fitness-bewerten [indiv]
;; count ist schneller als String.length
(+ (* 2 (Math/abs (- (count das-ziel) (count indiv))))
(reduce + (map #(if (= %1 %2) 0 1)
indiv das-ziel))))
Dabei machen wir uns zwei Eigenschaften von map zunutze: einerseits, dass über mehr als
eine Sequence iteriert werden kann, und andererseits, dass die Iteration abbricht, sobald das
Ende einer Sequence erreicht wurde. Bei Ungleichheit von zwei zu vergleichenden Zeichen wird
eine 1 an die Funktion reduce weitergerreicht, die somit die Addition der entdeckten
Unterschiede übernimmt. Erwähnenswert ist auch, dass die Java-Methode length für Strings
nicht verwendet wird, da sie (N) ist, während count auf Datenstrukturen (1)
garantiert.
Bei der Implementation der Gene wird zunächst die Menge der erlaubten Symbole
definiert und die Funktion zufaelliges-symbol zum zufälligen Ziehen eines solchen Symbols
bereitgestellt. Erzeugen eines zufälligen Index mit Hilfe der Anzahl der enthaltenen Symbole
ist ein verbreitetes Konstrukt. Die Erzeugung eines kompletten Gens – also eines zufälligen
Strings aus den erlaubten Symbolen – zeigt ein häufiges Muster aus der funktionalen
Programmierung: Mit Hilfe von repeatedly wird die Funktion zum Ziehen eines Symbols
wiederholt aufgerufen, und mit take wird davon eine gewisse Anzahl verwendet. Ohne take
würde repeatedly immer weiter Symbole erzeugen, eine Sequence, die nicht in den Speicher
eines Computers passt. Da take eine Sequence zurückliefert, sorgt apply dafür, dass
die Elemente dieser Sequence als einzelne Argumente der Funktion str übergeben
werden.
(def gen-max-laenge 20)
(def die-symbole
(str "abcdefghijklmnopqrstuvwxyz"
"ABCDEFGHIJKLMNOPQRSTUVWXYZ "))
(defn zufaelliges-symbol []
(nth die-symbole
(rand-int (count die-symbole))))
(defn zufaelliges-gen [laenge]
(apply str
(take (inc (rand-int laenge))
(repeatedly zufaelliges-symbol))))
Die folgenden drei Funktionen – gen-auswahl, laengen-auswahl
und gen-rekombination – implementieren gemeinsam die Rekombination. Die für
neue Einflüsse in der Population notwendige Mutation wird bei der Auswahl des
Gens hinzugezogen, und das Crossover-Verfahren entspricht nicht dem gängigen
1-Punkt-Crossover, bei dem die Gene der Eltern an einem Punkt zerschnitten und über Kreuz
wieder zusammengefügt werden, sondern basiert auf dem n × m-Crossover, den einer
der Autoren dieses Buches 2002 publiziert hat [38]. Dieser entscheidet bei jedem
Symbol zufällig, von welchem Elternteil es genommen werden soll. Da der Algorithmus
Schwierigkeiten hat, die korrekte Länge zu finden, wenn sie jedesmal zufällig neu
bestimmt wird, wurde in die Funktion zur Wahl einer Länge für einen Nachkommen eine
Bevorzugung der in der Population bereits vorhandenen Längen eingeführt. Mit diesen
beiden Hilfsfunktionen ist die Implementation der tatsächlichen Rekombination
einfach und verwendet wieder das schon beschriebene Muster mit apply, take und
repeatedly. An dieser Stelle kommt zusätzlich die Funktion cycle zum Einsatz, damit
die Iteration nicht vorzeitig aufgrund eines kürzeren Eltern-Gens abbricht. Da eine
Erklärung für das Funktionieren von genetischen Algorithmen auf der impliziten
Bildung von Informationsblöcken basiert, erscheint das mögliche Verschieben solcher
Blöcke durch cycle angebrachter als das Auffüllen mit zufälligen Symbolen auf die
Ziellänge.
(defn gen-auswahl [g1 g2]
(if (= 0 (rand-int 10)) ;; Mutation
(zufaelliges-symbol)
(if (= 0 (rand-int 2)) g1 g2)))
(defn laengen-auswahl [i1 i2]
(let [ci1 (count i1)
ci2 (count i2)]
;; 50% eine der beiden Laengen
(if (= 0 (rand-int 2))
(if (= 0 (rand-int 2))
ci1
ci2)
;; 50% eine zufaellige Laenge dazwischen
(max gen-max-laenge
(+ (min ci1 ci2)
(rand-int (Math/abs (- ci1 ci2))))))))
(defn gen-rekombination [i1 i2]
(apply str
(take (laengen-auswahl i1 i2)
(map gen-auswahl (cycle i1)
(cycle i2)))))
Der folgende Codeabschnitt befasst sich mit den Details der Population.
Die Größe wird festgelegt, die allerdings bei diesem Verfahren mehr ein Richtwert denn
ein absoluter Wert ist. Es wird versucht, diese Größe beizubehalten. Eine zufällige
Population ruft wiederholt die Funktion für zufällige Gene auf, verwendet davon
ausreichend für die angegebene Größe, evaluiert diese bezüglich ihrer Fitness und
speichert alle so erzeugten Gen-Fitness-Paare mit into in einer zuvor leeren Map. Das
Resultat kann dann verwendet werden, um das zentrale Atom der Population neu zu
setzen.
(def pop-groesse 1000)
(defn zufaellige-population [groesse indiv-laenge]
(into
{}
(map (fn [x] {x (fitness-bewerten x)})
(take groesse
(repeatedly
#(zufaelliges-gen indiv-laenge))))))
(defn irgendein-indiv [population]
(let [ks (keys population)]
(rand-nth ks)))
(defn selektiere-indiv [pop
selektions-druck
vorzug]
(let [cmp-fun (if (= vorzug :gut) < >)]
(first
(sort #(cmp-fun (pop %1) (pop %2))
(take selektions-druck
(repeatedly
#(irgendein-indiv pop)))))))
Für die fitnessbasierte Selektion kommt hier ein Tournament-Algorithmus
zum Einsatz, der durch die Funktionen irgendein-indiv und selektiere-indiv
implementiert wird. Die in irgendein-indiv verwendete Funktion rand-nth wurde erst in
Clojure 1.2 eingeführt. Sie kann für ältere Versionen von Clojure durch eine Kombination von
nth, count und rand-int ersetzt werden. Tournament-Selektion zieht eine gewisse Anzahl von
Individuen zufällig und nimmt schließlich das mit der besten Fitness. Durch die
Anzahl lässt sich der Selektionsdruck einfach steuern, und eine linear fitnessbasierte
Selektion wird durch das Ziehen von zwei Individuen statistisch erreicht. Da spätere
Programmteile die Selektion von schlechten Individuen benötigen werden, erlauben wir
die Angabe einer Richtung, die die Funktion zum Vergleichen zweier Individuen
bestimmt.
Jetzt übernehmen Agents die Steuerung der gesamten Evolution. Ein
einfacher Agent auf einem String enthält die Information, ob das System derzeit läuft oder
nicht (start-stop-agent). Neue Individuen werden durch Senden einer geeigneten
Aktionsfunktion an Agents erzeugt. Der Pool dieser Agents wird mit richte-wohnungen-ein
erzeugt und weiter unten in wohnungen gespeichert. Die Funktion a-day-in-the-life zieht
zwei Eltern, rekombiniert deren Gene zu einem neuen Individuum, bewertet es und speichert
es mit Hilfe von swap! in der Population. Clojure vereinfacht hier den konkurrierenden Zugriff
enorm.
(def ^{:doc "Agent, der das System weiterlaufen laesst"}
start-stop-agent (agent "stop"))
(def ^{:doc "Wohnungen werden an der REPL eingerichtet. In
jeder Wohnung lebt ein Agent, der neue Individuen erzeugt."}
wohnungen)
(def ^{:doc "Die Anzahl der Wohnungen muss auf den
Sensenmann abgestimmt sein, damit die Population nicht
waechst."}
anzahl-wohnungen 3)
(defn richte-wohnungen-ein []
(doall
(for [i (range anzahl-wohnungen)]
;; jeder Agent zaehlt die erzeugten Individuen;
(agent 0))))
(defn a-day-in-the-life
"Zentrale Funktion fuer das Fortschreiten der Evolution."
[]
(let [o1 (selektiere-indiv @population 3 :gut)
o2 (selektiere-indiv @population 3 :gut)
new (gen-rekombination o1 o2)
fit (fitness-bewerten new)]
(swap! population conj {new fit})))
(defn a-day-in-the-life-agent-fn [status]
;; Sende uns selbst wieder an den Agent
(when (= @start-stop-agent "running")
(send *agent* a-day-in-the-life-agent-fn))
(a-day-in-the-life)
(inc status))
Das Agent-Konstrukt beruht nun darauf, dass initial einmal die
Agent-Funktion a-day-in-the-life-agent-fn an einen Agent geschickt wird. Wenn das
System noch läuft – signalisiert durch den Status des Agent start-stop-agent –, wird
diese Funktion erneut an den aktuellen Agent, der in einer Agent-Funktion stets als
*agent* verfügbar ist, geschickt. Der Rückgabewert der Agent-Funktion ist der
inkrementierte Status, so dass jeder Agent die Zahl der durch ihn erzeugten Individuen
enthält.
(def sensenmann (agent 0))
(defn hauch-des-todes []
(when (> (count @population) pop-groesse)
(let [gen (selektiere-indiv
@population 2 :schlecht)]
(swap! population dissoc gen))))
(defn hauch-des-todes-agt-fun [status]
(when (= @start-stop-agent "running")
(send-off *agent* hauch-des-todes-agt-fun))
(hauch-des-todes)
(inc status))
Entfernen von Inidividuen
Mit demselben Verfahren wird die Population durch den
Agent sensenmann wieder reduziert. Dieser selektiert ein Individuum umgekehrt
fitnessbasiert und entfernt es dann mit disj aus der Population. Sein Zustand repräsentiert
aber die Anzahl der Aufrufe, nicht die Anzahl der entfernten Individuen. In diesem
Beispiel steht den erzeugenden Threads nur ein entfernender entgegen. Es ist je nach
Maschine die Anzahl der Threads so einzustellen, dass die Population nicht signifikant
wächst.
Die Funktionen, die an einen Agent geschickt werden, werden asynchron und in einem
dedizierten Thread-Pool verarbeitet. Auf diese Weise ist der Algorithmus automatisch
parallelisiert, ohne dass auf grundlegende Thread-Funktionen zurückgegriffen werden
muss.
Die letzten Funktionen im Listing erlauben den einfachen Zugriff auf die Evolution von
der REPL aus. Natürlich könnten auch alle Befehle einzeln eingetippt werden, aber auf diese
Weise ist es einfacher.
(defn fuelle-start-population []
(reset!
population
(zufaellige-population pop-groesse gen-max-laenge)))
(defn bereite-evolution-vor []
(fuelle-start-population)
(send sensenmann (constantly 0))
(def wohnungen (richte-wohnungen-ein)))
(defn starte-evolution []
(send start-stop-agent (constantly "running"))
(await start-stop-agent)
(send sensenmann hauch-des-todes-agt-fun)
(map #(send % a-day-in-the-life-agent-fn)
wohnungen))
(defn stop-evolution []
(send start-stop-agent (constantly "stopped")))
(defn beste-individuen
([anz] (let [p @population]
(take anz (sort #(< (p (first %1))
(p (first %2)))
p))))
([] (beste-individuen 1)))
(defn verfolge-evolution []
(while (= @start-stop-agent "running")
(let [beste (beste-individuen 2)
anzahl (count @population)]
(printf "Population: %d" anzahl)
(println " - Wohnungen: " (map deref wohnungen))
(println beste)
(when (= 0 (second (first beste)))
(stop-evolution))
(Thread/sleep 2000))))
Die Population wird zu Beginn einmal mit reset! auf eine zufällige
Population gesetzt, und die Agents machen es sich in den Wohnungen bequem. Anschließend
werden die notwendigen Aktionsfunktionen an die verschiedenen Agents geschickt, die den
Start bewirken. Erwähnenswert ist hier die Verwendung von start-stop-agent, für den die
Aktionsfunktion erst durch Aufruf der Funktion constantly erzeugt wird. Diese gibt eine
neue Funktion zurück, die immer den konstanten Wert liefert. Warten auf AgentDamit die
Agents in den Wohnungen und der Sensenmann nicht eventuell sofort wieder ihre
Arbeit einstellen, weil die asynchrone Bearbeitung des Start-Stop-Agent noch nicht
durchgeführt wurde, wartet die Funktion starte-evolution mit Hilfe von await
darauf.
Während die Threads des Agent-Pools im Hintergrund ihre Arbeit
machen, kann jederzeit mit beste-individuen beobachtet werden, wie nah die Population
dem Ziel bereits ist. Diese Funktion wird mit zwei Argument-Listen definiert: ohne
Argumente und mit der Anzahl der zu zeigenden Individuen. Die letzte Funktion
schließlich, verfolge-evolution, automatisiert die Beobachtung bis zum Erreichen
des Ziels. Ein beispielhafter Durchlauf durch dieses Programm zeigt der folgende
REPL-Mitschnitt:
de.clojure-buch.genalg> (bereite-evolution-vor)
#’de.clojure-buch.genalg/wohnungen
de.clojure-buch.genalg> (starte-evolution)
(#<Agent@20d144ae: 0> #<Agent@af40c57: 0>
#<Agent@1c56295f: 0>)
de.clojure-buch.genalg> (verfolge-evolution)
Population: 1005 - Wohnungen: (338 297 316)
([QhSjIBaftbfKC 11] [cZsosduzeXwHQ 11])
Population: 1012 - Wohnungen: (612 565 612)
([dtCyVcaqxnPHt 11] [TUSyldGwDTjay 11])
Population: 1055 - Wohnungen: (899 825 936)
([ZlerldRuNNNOf 10] [phsd dRrgdtNt 10])
Population: 1040 - Wohnungen: (1184 1086 1220)
([KcTrPdVbJkSmt 10] [pheOnBnELJeDt 10])
Population: 1022 - Wohnungen: (1469 1392 1459)
([ThaPDHFyPZ xj 9] [QDprVAayBXxOt 9])
Population: 1011 - Wohnungen: (1724 1664 1765)
([ThgrydsyPxxCt 7] [SwxrWday HF E 8])
Population: 1042 - Wohnungen: (2016 1934 2038)
([chursdaXexkvt 6] [ThgrydsyPxxCt 7])
Population: 1086 - Wohnungen: (2289 2209 2329)
([chursdaXexkvt 6] [TwCFEdaV Neat 6])
Population: 1010 - Wohnungen: (2832 2784 2823)
([ahurCxay NHrt 5] [ShurCdayxNOrt 5])
Population: 1015 - Wohnungen: (3089 3064 3110)
([hhVrEXay Next 4] [sWYrsdVy Neyt 5])
Population: 1030 - Wohnungen: (3348 3358 3370)
([ThurCdAylNext 3] [MhursdFy Zzxt 4])
Population: 1041 - Wohnungen: (3615 3652 3631)
([ThursdayeNkxt 2] [ThupsdayxNrxt 3])
Population: 1004 - Wohnungen: (3876 3909 3892)
([Thirjday Next 2] [ThursdayeNkxt 2])
Population: 1020 - Wohnungen: (4138 4193 4172)
([ThursdayJoext 2] [Th rsday NeZt 2])
Population: 1008 - Wohnungen: (4426 4476 4442)
([Thursday Next 0] [ThuAsday Next 1])
nil