Clojure zu lernen ist ein spannendes Abenteuer. Wer bereits über Erfahrungen mit Lisp – vor
allem Common Lisp – verfügt, wird einige liebgewonnene Spracheigenschaften vermissen, aber
neue entdecken. Für Programmierer ohne Erfahrungen mit Lisp oder funktionaler
Programmierung bedeutet der Einstieg in Clojure einen viel größeren Umbruch. Die
Möglichkeit, ganz neue Konstrukte und Methoden zu lernen, ist für manche Grund genug, eine
neue Programmiersprache in Angriff zu nehmen.
Clojure enthält zahlreiche interessante Features, es ist aber andererseits auch noch jung und in
einigen Bereichen noch nicht ausgereift. Gerade Common Lisp trägt durch sein Alter viel
Geschichte mit sich herum, die auch dazu geführt hat, dass viele Sonderfälle ans Tageslicht
getreten sind und gelöst wurden. Aber auch Java hat ausreichend Jahre und Anwendungsfälle
auf dem Buckel, dass es seine Kinderkrankheiten durchlebt haben dürfte. Clojure muss diese
Phase der Entwicklung erst noch durchlaufen, auch wenn es durch sein Erbe von Lisp und
Java sehr stabil ist. Vor allem in den Bereichen, in denen Clojure Neuland betritt, ist noch mit
Ecken und Kanten zu rechnen. BlogsDie Neigung vieler Programmierer, sich in Form
eines Blogs der Welt mitzuteilen, erlaubt es, uns einen Eindruck zu verschaffen, wie
Clojure aufgenommen wird und, für diesen Abschnitt relevant, welche Teile auf Kritik
stoßen.
Einer der größten Kritikpunkte ist die Schwierigkeit des Debuggens. Das liegt vor
allem daran, dass die Stacktraces, die im Falle einer Exception angezeigt werden, in den
seltensten Fällen geeignet sind, die Ursache der Exception zu ermitteln. Wer einmal einen
Stacktrace von Common Lisp untersucht hat, in dem es möglich ist, sich jede lokale Variable,
jedes Argument, jede Funktion bis hin zum kompilierten Code einer Funktion anzuschauen,
wird von Javas Stacktraces sehr enttäuscht sein. Hinzu kommt, dass durch die Codeerzeugung
durch Bytecode-Manipulation (siehe auch Abschnitt 4.8) der Bezug zum Clojure-Code oft
zusätzlich verschleiert wird. Hier muss die Entwicklergemeinschaft von Clojure dringend
Lösungen finden, da dieses Problem das Potenzial hat, die Verbreitung von Clojure
massiv zu behindern. Die Clojure-Gemeinde ist sich dessen bewusst und in jüngerer
Vergangenheit wurden in dieser Hinsicht bereits Fortschritte gemacht. Debuggen mit den
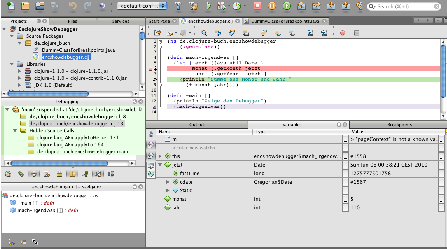
etablierten Java-Werkzeugen ist prinzipiell möglich, wie Abbildung 7.1 demonstriert, aber
auch dies ist noch etwas hakelig in der Verwendung. Ein gelungene Verbindung der
Werkzeuge, die die JVM anbietet, mit den Vorgehensweisen aus der Lisp-Welt erscheint
wünschenswert.
Rich Hickey hat für viele Entscheidungen, die mit bisherigen
Lisp-Konventionen brechen, gute Erklärungen. Die Entscheidung, das Komma als Whitespace
zu betrachten, fällt nicht in diese Gruppe. Die Vorteile sind gering (Gewohnheit der
Java-Programmierer und marginale Verbesserung der Lesbarkeit durch Gruppieren von
Schlüssel-Wert-Paaren bei Maps), die Nachteile wiegen aber auch nicht schwer (Bruch mit
Lisp-Konvention, die das Komma in Makros so verwendet wie Clojure die Tilde, umstrittene
Verschlechterung der Lesbarkeit von Makrodefinitionen), so dass dieser Punkt als relativ
unwichtig betrachtet werden dürfte. Ebenso die Einbeziehung von eckigen und geschweiften
Klammern, deren korrekte Verwendung an den meisten Codestellen leicht von den
Fingern geht, aber vor allem beim Schließen tief geschachtelter Codeteile störend
auffällt.
Clojure ist ein „Lisp-1“, bei dem sich Variablen und Funktionen den gleichen
Namensraum teilen, Common Lisp hingegen ist ein „Lisp-2“, für das dies nicht gilt. Zusammen
mit der Neigung von Lisps, kurze und prägnante Funktionsnamen zu vergeben, führt das dazu,
dass die „guten“ Namen für lokale Variablen oft schon vergeben sind. Das führt zwar nur dann
zu einem Problem, wenn die Funktion gleichen Namens zur Anwendung kommen
soll, kann aber Leser der Funktion verwirren. Andererseits hat diese Entscheidung
auch Vorteile. Wo immer Funktionen verwendet werden, braucht es keine explizite
Syntax oder Aufrufe. Anstatt eine Funktion in einer Variablen zu speichern und
funcall mit dieser aufzurufen, kann die Variable direkt an Stelle des Funktionsnamen
stehen.
Fehlende Endrekursion wird ebenfalls oft genannt und mit der fehlenden
Funktion in der JVM begründet. Doch geht dieses Argument nicht weit genug, denn
Clojure kann die explizite Rekursion mit loop und recur optimieren, was unter
Umständen auch auf „echte“ Endrekursion erweitert werden könnte. In der Arbeit
mit Clojure erweist sich die Form als gut zu verwenden und unserer Meinung nach
ist sie sogar vorteilhaft, gerade weil sie die Intention explizit ausdrückt. Sie kann
so auch durch den Compiler überprüft werden und ist für den Leser leichter zu
erkennen.
Die Tatsache, dass Metadaten auf Clojure-Typen beschränkt sind, ist
derzeit wohl am ehesten durch die Implementation von Metadaten innerhalb der jeweiligen
Klassen zu erklären. Eine Alternative für Java-Objekte könnte darin bestehen, deren
Metadaten in einer externen Datenstruktur zu halten. Diese Aussage spiegelt jedoch nicht die
Meinung der Clojure-Entwickler, sondern unsere Auffassung zur Implementation wider. Eng
verwandt mit Metadaten ist die explizite Angabe des Typs einer Variablen. Diese wird
allgemein als eher unschön oder gar hässlich empfunden. Diskussionen auf der Mailingliste
deuten darauf hin, dass sich die kommende Version von Clojure mit Optimierungen
im Typsystem beschäftigen wird. Ob ein System zur Typinferenz nach Art von
Hindley-Milner, wie es etwa in Haskell und Scala zu finden ist, in Clojure verwendet werden
könnte, etwa um für den Anwender unbemerkte Optimierungen durchzuführen, bleibt
anzuwarten.
Vor allem von Entwicklern, die Common Lisp favorisieren, kommt Kritik am
Einsatz der JVM. Andere führen dies als ausdrücklichen Vorteil von Clojure an. Somit ist der
Einsatz der JVM nicht unumstritten. Gleiches gilt für das STM-System. Hier kommt Kritik in
erster Linie von erfahrenen Entwicklern, die Locking gut beherrschen und ihre Probleme damit
lösen können.
Ein Ausgangspunkt für die Suche nach Meinungen und Kritik zu Clojure ist der
Blogeintrag von Stephen Bach [5]. Zwei andere lesenswerte Quellen sind die Diskussion um
„Multithreaded Memoize“, die Meikel Brandmeyer zusammengefasst hat [9] sowie ein Thread
in der Clojure-Gruppe, in dem es um langlaufende Transaktionen geht [61]. In diesen
Diskussionen wurden die Hintergründe der STM-Maschinerie und Probleme beim
Multithreading umfassend besprochen. Unabhängig von den jeweiligen Resultaten dieser
Diskussionen sieht es für uns so aus, als würde Clojure seinem Anspruch, Multithreading für
die Massen leicht verfügbar zu machen, noch nicht ganz gerecht. Teilweise ist noch zu viel
Hintergrundwissen notwendig, um STM korrekt einzusetzen. Hier wird sich im Laufe der Zeit
sicherlich noch einiges tun, zumal auch die Performance der STM noch nicht flächendeckend
getestet ist.
Clojure enthält heute einige interessante neue Technologien: die persistenten Datenstrukturen
und vor allem STM. Mit Spannung erwarten wir den weiteren Verlauf und ob sich diese
Technologien werden durchsetzen können. Auch die Frage, inwieweit sich die Einführung von
Protokollen und Datentypen auf die Entwicklung der Sprache auswirken wird, ist
offen.
Clojure in Clojure ist sicherlich ein wichtiges nächstes Projekt, aber auch die
Entwicklung einer wichtigen Applikation in Clojure steht noch aus. Gemeinhin gilt das als ein
weiteres Kriterium dafür, ob sich eine Sprache durchsetzen kann, und dieser Test steht bei
Clojure noch aus. Im Netz entstehen die ersten Webapplikationen, die in Clojure
implementiert sind: „The Deadline“ [59], das bereits genannte Clojars [51] oder auch
„DocuHarvest“[16] etwa sind vielversprechende Projekte.
Lebenszeit von Variablenbindungen
Lifetime-Management von Clojures Variablenbindungen, vor
allem von lokalen Bindungen etwa in einem let, ist ein offener Punkt, der allerdings keine
großen Veränderungen bewirken sollte. Ein ähnlicher Umfang ist zu erwarten, wenn mehr und
mehr Operationen auf native Objekte der Host-Plattform zurückgreifen oder dem
Entwickler Mittel an die Hand gegeben werden, dies zu erreichen. Das sollte, neben
anderen Optimierungen durch den Compiler, die Performance noch einmal ein wenig
verbessern.
Beachtenswert ist auch die Spielwiese Clojure Contrib. Clojure 1.2 hat gezeigt, dass
es die Perlen unter den dortigen Bibliotheken in den Lieferumfang von Clojure schaffen
können. Diskutiert wurde auch bereits das Build-System von Clojure Contrib. Derzeit entsteht
ein großes JAR-File, denkbar sind aber auch Builds der einzelnen Bestandteile und ein
Abhängigkeitsmanagement etwa mit Maven.
Bei der Arbeit mit Threads im Allgemeinen und dem Pool der
Agents im Besonderen fällt auf, dass es für Agents nur zwei Thread-Pools gibt. Es
fällt nicht schwer, sich vorzustellen, dass das Management von Threads und deren
Prioritäten sowie von verschiedenen Thread-Pools im Laufe der Zeit an Bedeutung
gewinnen wird. Die stetige Arbeit am Prozess-Scheduler des Linux-Kernels etwa
zeigt, dass dieses Thema nicht im Vorbeigehen lösbar ist. Auf einen Vorschlag von
Alex Miller [47] hat Rich Hickey positiv reagiert und angedeutet, dass nach der
Veröffentlichung von Clojure 1.2 in dieser Richtung etwas unternommen werden
könnte.
Mit dem soeben erfolgten Blick in die Kristallkugel fällt der Vorhang für dieses Buch. Wir
hoffen, dass wir einen leichten Einstieg, umfangreiches Alltagswissen und einige interessante
Hintergründe vermitteln konnten. Die Gemeinschaft der Clojure-Entwickler und -Anwender ist
ausgesprochen freundlich, und im IRC-Kanal wie auch auf der Mailingliste ist jeder herzlich
willkommen.